고정 헤더 영역
상세 컨텐츠
본문
728x90
Level 1 문제들만 계속 풀다가 어느정도 감도 익힌것 같아 Level 2 문제들과 병행하는 즁,,
전보다는 풀만하지만 그래도 어렵다ㅠㅠ 이래서 Level 3 이상은 어떻게 하나
그래도 나름 해설 안보고 혼자 생각해서 푸는 문제들이 생겼다 😏
기분 좋으니까 내가 푼 방식과 시행착오들 잊지 않게 적어두기(연습문제는 다른 문제들보다 쉬워서 대부분 패스)
JadenCase 문자열 만들기
코딩테스트 연습 > 연습문제 > JadenCase 문자열 만들기 https://programmers.co.kr/learn/courses/30/lessons/12951
코딩테스트 연습 - JadenCase 문자열 만들기
JadenCase란 모든 단어의 첫 문자가 대문자이고, 그 외의 알파벳은 소문자인 문자열입니다. 문자열 s가 주어졌을 때, s를 JadenCase로 바꾼 문자열을 리턴하는 함수, solution을 완성해주세요. 제한 조건
programmers.co.kr
1) 내 풀이
첫 글자는 대문자로 지정한 후 이전 글자가 빈칸인지 아닌지 확인하여 단어를 시작하는 첫 글자인지 판단
def solution(str):
s_list = list(str)
answer = s_list[0].upper() # 처음은 무조건 대문자로 시작
for i in range(1, len(s_list)):
if s_list[i-1] == ' ': # 이전 문자가 빈칸이라면 현재 문자는 단어의 첫글자
answer += s_list[i].upper()
else: # 아니라면 소문자
answer += s_list[i].lower()
return answer2) 내장 함수 사용
def solution(s):
return s.title()3) 나랑 비슷하지만 더 짧은 코드
string.split() 인자가 주어지면 해당 인자로, 빈칸으로 주어지면 공백으로 나눠 문자열들의 리스트로 반환
def Jaden_Case(s):
answer =[]
for i in range(len(s.split())): # s.split() 문자열 리스트 반환
answer.append(s.split()[i][0].upper() + s.split()[i].lower()[1:])
return " ".join(answer)
전력망을 둘로 나누기
코딩테스트 연습 > 위클리 챌린지 > 전력망을 둘로 나누기 https://programmers.co.kr/learn/courses/30/lessons/86971
코딩테스트 연습 - 전력망을 둘로 나누기
9 [[1,3],[2,3],[3,4],[4,5],[4,6],[4,7],[7,8],[7,9]] 3 7 [[1,2],[2,7],[3,7],[3,4],[4,5],[6,7]] 1
programmers.co.kr
대충 그래프 문제인 것은 알겠어서 DFS나 BFS를 써야겠다고 생각했는데.. 푸는데 좀 걸렸다 ㅠㅠ
1) 노드 수를 세려했던 바보 같은 방법
함수 실행 부분에서 for문
for i in range(1, len(wires)-1): # 전체 노드 수
# 삭제할 간선 wires[i]
t1 = search(wires[:i], n)
t2 = search(wires[i+1:], n)처음에는 단순히 어차피 이어진 그래프인디 각각 그래프에 있는 노드 수 구하면 되는거 아녀? 하고 짰던 코드
def search(wire, n):
start = wire.pop()
visit_nodes = [start[0], start[1]]
while wire:
current = wire.pop()
if current[0] not in visit_nodes:
visit_nodes.append(current[0])
if current[1] not in visit_nodes:
visit_nodes.append(current[1])
return visit_nodes노드끼리 다 연결된 것도 아닌데.. 지금보면 참 말도 안되는 코드인 듯..
2) 간선 정보를 이용하고자 했던 방법
위의 방법에서 노드 방문 여부를 확인하다가 간선을 지나갔는지 간선의 방문 여부를 체크해보자 하고 짠 코드
def bfs(wire, n):
start = wire.pop()
visit_nodes = [start[0], start[1]]
visited = [[0 for _ in range(n)] for _ in range(n)] # 간선 정보 담긴 dict 초기화
for i in range(n): # 자기 자신과의 간선의 연결 정보 True
visited[i][i] = 1
visited[start[0]-1][start[1]-1] = 1 # 첫 간선 True
while wire:
current = wire.pop()
if visited[current[0]-1][current[1]-1] == 0:
visited[current[0]-1][current[1]-1] = 1 # 간선 방문 check
if current[0] not in visit_nodes: # 방문한 노드가 아니라면 추가
visit_nodes.append(current[0])
if current[1] not in visit_nodes:
visit_nodes.append(current[1])
else:
continue
return visit_nodes지금 보면 코드는 별거 없지만 얻은 수확이 있다면
* 배열 초기화 방법
- 1차원 배열
list = [0 for _ in range(n)] # n개의 0으로 이뤄진 1차원 배열- 2차원 배열
list = [[0] * n)] * m
list = [[0 for _ in range(n)] for _ in range(m)]첫번째 방법으로 하면 주소도 같이 복사되서 이후 인덱스로 배열값에 접근할 때 중복으로 선택되는 문제가 발생한다ㅠ 이거때매 시간 좀 날린듯
따라서 2차원 배열 초기화시 두번째 방법을 사용할 것
3) BFS 이용한 정답
먼저 함수 실행부분
from collections import defaultdict
def solution(n, wires):
answer = []
for i in range(0, len(wires)):
tmp_wires = wires.copy()
del tmp_wires[i] # 각각의 간선을 모두 삭제해보면서 모든 경우의 수 저장
wires_dict = defaultdict(set) # 주어진 간선 위주의 그래프 정보를 노드 위주로 변경
for w in tmp_wires:
wires_dict[w[0]].add(w[1])
wires_dict[w[1]].add(w[0])
t1 = bfs(wires_dict, wires[i][0]) # 두 그래프 각각 탐색
t2 = bfs(wires_dict, wires[i][1])
answer.append(abs(len(t1) - len(t2))) # 그래프 탐색결과 길이의 차이 저장
return min(answer) # 차이가 가장 작은 경우 반환큰 트리에서 간선 하나를 삭제함으로써 나눠진 두 그래프를 탐색하고 그 결과를 모두 저장해 그 중 차이가 최소인 것을 찾으려함(완전탐색라 해도되나,,)
어려웠던 부분은 입력되는 그래프 정보는 간선 위주로 [[1,3],[2,3],[3,4],[4,5],[4,6],[4,7],[7,8],[7,9]] 이처럼 양쪽 노드 번호로 주어진다..
하지만 내가 아는 탐색 알고리즘들은 {노드 : [간선으로 이어진 노드들]} 이렇게 정보가 주어져서 이에 맞춰 dict형태로 데이터의 모습을 바꿔줬다
근데 다른 코드들을 보니 보통 다들 이렇게 바꾸더라..! 아니면 바꾸면서 막 어떻게 하던데 난 모르겠음
def bfs(graph, start_node):
visit = list()
queue = list()
queue.append(start_node)
while queue:
node = queue.pop(0)
if node not in visit:
visit.append(node)
queue.extend(graph[node])
return visitBFS 코드는 간단하게 방문한 노드들을 반환한다.
문자열 압축
코딩테스트 연습 > 2020 KAKAO BLIND RECRUITMENT > 문자열 압축 https://programmers.co.kr/learn/courses/30/lessons/60057
코딩테스트 연습 - 문자열 압축
데이터 처리 전문가가 되고 싶은 "어피치"는 문자열을 압축하는 방법에 대해 공부를 하고 있습니다. 최근에 대량의 데이터 처리를 위한 간단한 비손실 압축 방법에 대해 공부를 하고 있는데, 문
programmers.co.kr
처음으로 나 혼자 푼 카카오문제.. 카카오문제중에서는 좀 쉬운편인거 같지만 그래도 나름 뿌듯
주의해야할 점
- 문자열 슬라이싱할 때 마지막 인덱스는 들어가지 않는다는 점
- 첫번째 문자를 시작으로 반복하는 문자열 찾기를 시작할 것
입출력예시 5번에서 "xababcdcdababcdcd"은 첫 글자부터 반복되는 문자열이 없음으로 압축하지 못함
- 반복되는 문자열의 길이는 모두 같아야함
입출력예시 3번에서 "abcabcdede"이 "3abc2de"가 될 수 없는 이유는 반복되는 문자열 abc와 de의 길이가 같지 않기 때문
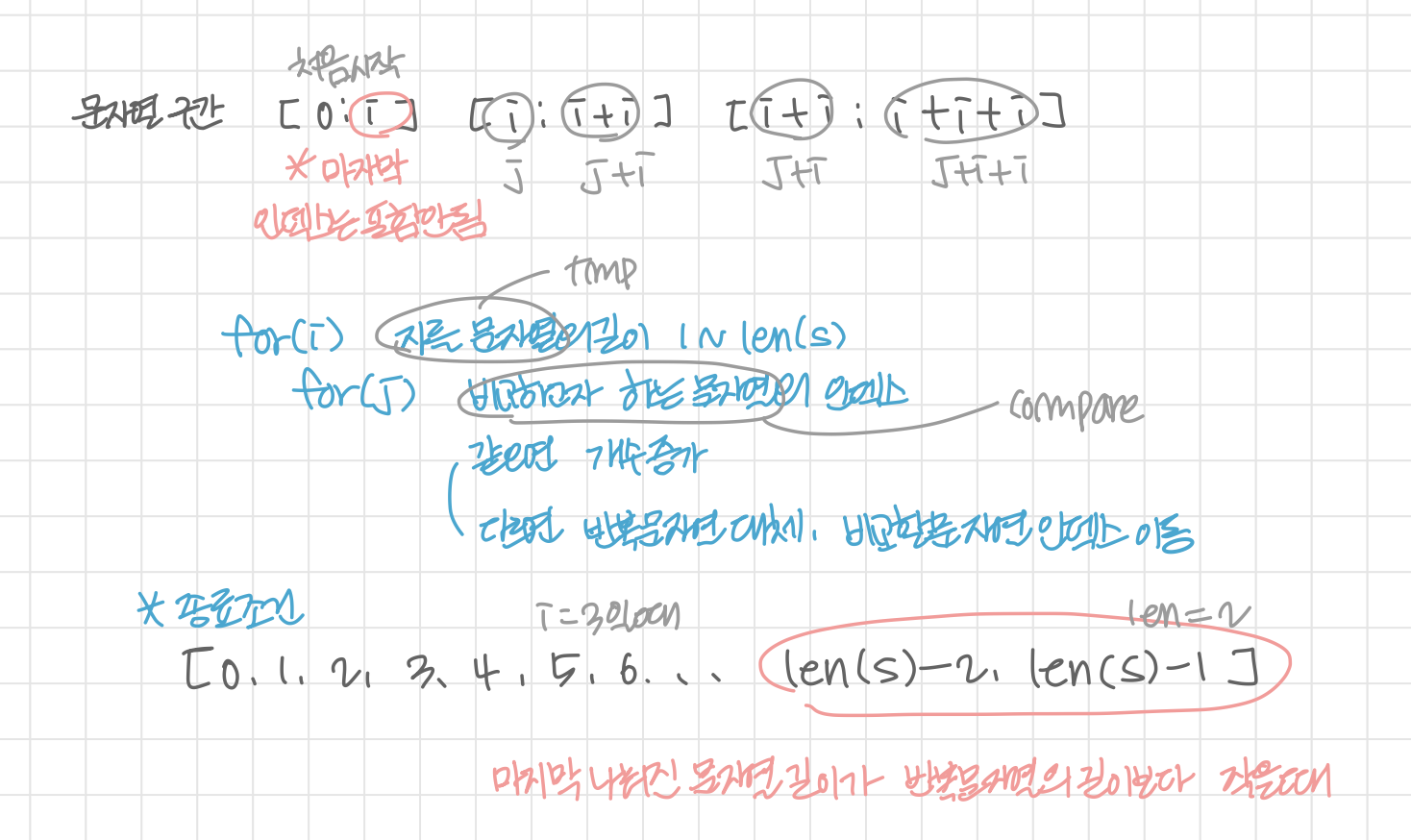
def solution(s):
answer = [] # 모든 길이의 tmp로 압축했을 때의 문자열 길이 배열
answer_s = '' # 압축된 문자열
for i in range(1, len(s) + 1): # tmp 1~len(s) 모든 길이 가능
tmp = s[0:i]
cnt = 1
j = i
while True:
compare = s[j:j+i]
if tmp == compare: # 뒤의 동일한 길이의 문자열과 같을 경우
cnt += 1
else: # 다를 경우
answer_s = answer_s + str(cnt) + tmp if cnt > 1 else answer_s + tmp # 압축된 문자열 추가
cnt = 1 # 개수 초기화
tmp = compare # 반복되는 문자열 전환
j += i # 다음 문자열로 이동
if len(s[j-i-1:]) < i: # 위에서 다음으로 이동했음으로 다시 i만큼 빼주고 마지막 잘라진 문자열 확인
answer_s += tmp # 나머지 문자열(반복되거나 나눠지지 않는 문자열) 뒤에 붙여줌
answer.append(len(answer_s))
answer_s = ''
break
return min(answer) # 길이가 가장 짧은 값 반환그림에서처럼 문자열 전체를 길이 i만큼 조각내서 한 조각을 기준조각(tmp)로 잡고 바로 다음에 오는 조각을 비교조각(compare)로 두어 비교했다.
같을 경우 기준조각이 반복되는 횟수(cnt)를 증가시켰고
둘이 같지 않을 경우 기준조각을 비교조각으로 바꿔주고 그 비교조각 다음 조각을 비교조각으로 바꿔준다.
종료 조건은 마지막으로 나눠진 조각이 기준조각 길이만큼 되지 않을 때로 나머지 문자열을 압축 문자열에 이어준 후 끝이 난다.
* 위에서 j에 i를 한번 더해줬기 때문에 j-i에 마지막 조각과 기준조각 길이가 같은 경우에도 끝내기 위해 -1까지 해줌
처음에는 비교 문자열 길이가 굳이 len(s)까지일 필요 없다고 생각하여
for i in range(1, int(len(s)/2) + 1)이렇게 절반길이까지 해줬었는데 이러면 테스트케이스5번에서 통과되지 못한다.
다른 댓글을 보니 길이가 1인 문자열에서 걸리는 문제라고 하여 코드를 위처럼 수정해주었다!
최댓값과 최솟값
코딩테스트 연습 > 연습문제 > 최댓값과 최솟값 https://programmers.co.kr/learn/courses/30/lessons/12939
코딩테스트 연습 - 최댓값과 최솟값
문자열 s에는 공백으로 구분된 숫자들이 저장되어 있습니다. str에 나타나는 숫자 중 최소값과 최대값을 찾아 이를 "(최소값) (최대값)"형태의 문자열을 반환하는 함수, solution을 완성하세요. 예를
programmers.co.kr
1) 내 풀이
def solution(s):
nums = s.split(' ')
nums = [int(num) for num in nums]
answer = str(min(nums)) + ' ' + str(max(nums))
return answer2) map() 이용하여 짧아진 코드
def solution(s):
s = list(map(int, s.split()))
return str(min(s)) + " " + str(max(s))
최솟값 만들기
코딩테스트 연습 > 연습문제 > 최솟값 만들기 https://programmers.co.kr/learn/courses/30/lessons/12941
코딩테스트 연습 - 최솟값 만들기
길이가 같은 배열 A, B 두개가 있습니다. 각 배열은 자연수로 이루어져 있습니다. 배열 A, B에서 각각 한 개의 숫자를 뽑아 두 수를 곱합니다. 이러한 과정을 배열의 길이만큼 반복하며, 두 수를 곱
programmers.co.kr
def solution(A, B):
answer = 0
A = sorted(A)
B = sorted(B, reverse=True)
for a, b in zip(A, B):
answer += a*b
return answer처음에 모든 경우의 수를 구해 가장 작은 값을 구해야하는 문제인 줄 알고 엄청 고민하다 간단한 풀이보고 당황
처음에는 정답 풀이를 이해 못했었지만 다시 보니 이해가 간다.. 가장 작은 수는 가장 큰 수와 곱해 다 합했을 때 값을 제일 작도록 하는듯함!
행렬의 곱셈
코딩테스트 연습 > 연습문제 > 행렬의 곱셈 https://programmers.co.kr/learn/courses/30/lessons/12949
코딩테스트 연습 - 행렬의 곱셈
[[2, 3, 2], [4, 2, 4], [3, 1, 4]] [[5, 4, 3], [2, 4, 1], [3, 1, 1]] [[22, 22, 11], [36, 28, 18], [29, 20, 14]]
programmers.co.kr
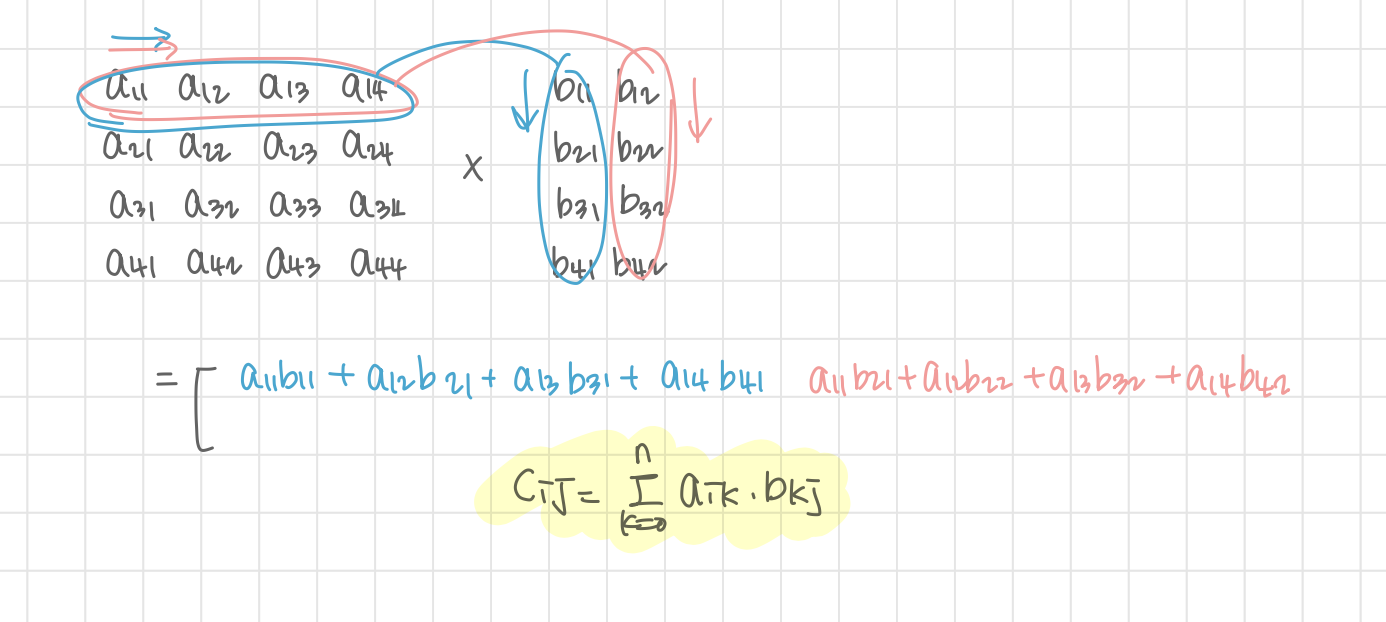
행렬 곱셈하는 방법을 몰라서 조금 해매다가 공식 찾아서 쉽게 해결
def solution(arr1, arr2):
# answer = [[0 for _ in range(len(arr2[0]))]] * len(arr1)
answer = [[0 for _ in range(len(arr2[0]))] for _ in range(len(arr1))] # 정답 행렬 0으로 초기화
for i in range(len(arr1)):
for j in range(len(arr2[0])):
for k in range(len(arr1[0])):
answer[i][j] += (arr1[i][k] * arr2[k][j])
return answer여기서도 마찬가지로 2차원 배열 초기화할때 주소값 복사하는 위의 방법 안쓰고 for문 사용하도록 주의할 것
그리고 효율은 for문 때문에 어쩔 수 없는 듯 ㅠㅠ
728x90
'취준 > 2. 코딩테스트' 카테고리의 다른 글
| [CODILITY] 코딜리티 문제풀이 파이썬 L1.Iterations ~ L2.Arrays (0) | 2022.01.14 |
|---|---|
| [PROGRAMMERS] 프로그래머스 코딩테스트 연습 > Level 2 & python3 문제풀이 ~ 11.04 (0) | 2021.11.05 |
| [PROGRAMMERS] 프로그래머스 코딩테스트 연습 > 깊이/너비 우선 탐색(DFS/BFS) 파이썬 문제풀이 (0) | 2021.09.11 |
| [PROGRAMMERS] 프로그래머스 코딩테스트 연습 > 완전탐색 파이썬 문제풀이 (0) | 2021.09.09 |
| [PROGRAMMERS] 프로그래머스 코딩테스트 연습 > 정렬(sort) 파이썬 문제풀이 (0) | 2021.09.09 |
댓글 영역