고정 헤더 영역
상세 컨텐츠
본문
728x90
멋쟁이사자처럼 X K-DIGITAL Training - 07.09
[github] https://github.com/ijo0r98/likelion-kdigital/tree/main/mid-project-1
ijo0r98/likelion-kdigital
멋쟁이사자처럼 & K-DIGITAL. Contribute to ijo0r98/likelion-kdigital development by creating an account on GitHub.
github.com
[참고] https://diane-space.tistory.com/90
[추천시스템] 넷플릭스 영화 추천 시스템 구현 파이썬 코드
데이터 필요한 데이터만 첨부 코드 import pandas as pd import numpy as np # 데이터 읽어오기 movies=pd.read_csv("movies.csv") ratings=pd.read_csv("ratings.csv") # 아이템 기반 협업 필터링 data=pd.merg..
diane-space.tistory.com
이전 세미1을 진행했던 팀원분들과 미드프로젝트1도 함께 진행하게 되었다.
원래는 두 문장 간의 유사도 판정을 하려했으나.. 너무 어려운점이 많아서 주제를 바꿨다.
단순히 문장의 길이나 단어의 유사도 판별 뿐 아니라 유의어도 있고, 또 단어를 비슷하게 썼다해서 비슷한 의미의 문장이 되는것도 아니다😅
강사님의 조언과 함께 바꾼 주제는 바로바로 캐글에 있는 영화 데이터!!
관련하여 참고할 자료도 많고 좀 더 친근한 주제라 생각되어 바꾸길 잘한것 같다 (내가 골랐당 흐흐)
같은 데이터로 팀원들과 부분을 나눠 서로 다른 분석, 예측모델을 만들어보기도 하고 같은 작업을 서로 다르게 해보고 하고 있다.
내용이 많아 정리되면 깃에는 올리겠지만 포스팅에는 간단히 내가 한 분석과 예측모델만 담아볼까 한다.
늘 느끼지만 다들 잘하시고.. 다른 분들 코드보며 배우는 점이 많은 것 같다.
나는 주로 사용자가 영화마다 매긴 별점데이터를 기준으로 분석하였고 크게 두 주제로 나뉜다.
○ 영화 추천
사용자가 영화마다 매긴 별점 데이터를 이용하여 사용자간의 유사도를 구하고 나와 비슷한 취향의 사용자를 찾아 이를 기반으로 영화를 추천받는다.
○ 사용자의 별점 예측
영화에 대한 정보들이 사용자가 별점을 매기는데 영향이 있을 것으로 예상하고 영화에 대한 메타데이터를 통해 사용자의 별점을 예측한다.
데이터 소개
https://www.kaggle.com/rounakbanik/the-movies-dataset
The Movies Dataset
Metadata on over 45,000 movies. 26 million ratings from over 270,000 users.
www.kaggle.com
movies = pd.read_csv('data/movies.csv')
ratings = pd.read_csv('data/ratings_small.csv')
metadata = pd.read_csv('data/movies_metadata.csv')
links = pd.read_csv('data/links.csv')ratings(ratings_small) : 사용자가 영화마다 매긴 별점 정보
movies : ratings의 movieId에 대응하여 영화에 대한 간단한 정보(제목, 장르) 포함
movies_metadata : 영화에 대한 자세한 정보 (평균 별점, 제목, 예산, 관람등급, 언어, 제작 국가, 상영시간, 리뷰 수 등)
links : metadata와 ratings, moives 사이 id 연결 정보
사용자 코사인 유사도 기반 영화 추천
1. 데이터 전처리
# dataframe merge
df = pd.merge(ratings, movies, on='movieId')# 사용자 기준 pivot table
df_matrix_user = df.pivot_table(index='userId', columns='title', values='rating')
# 결측치 0으로 채움
df_matrix_user.fillna(0, inplace=True)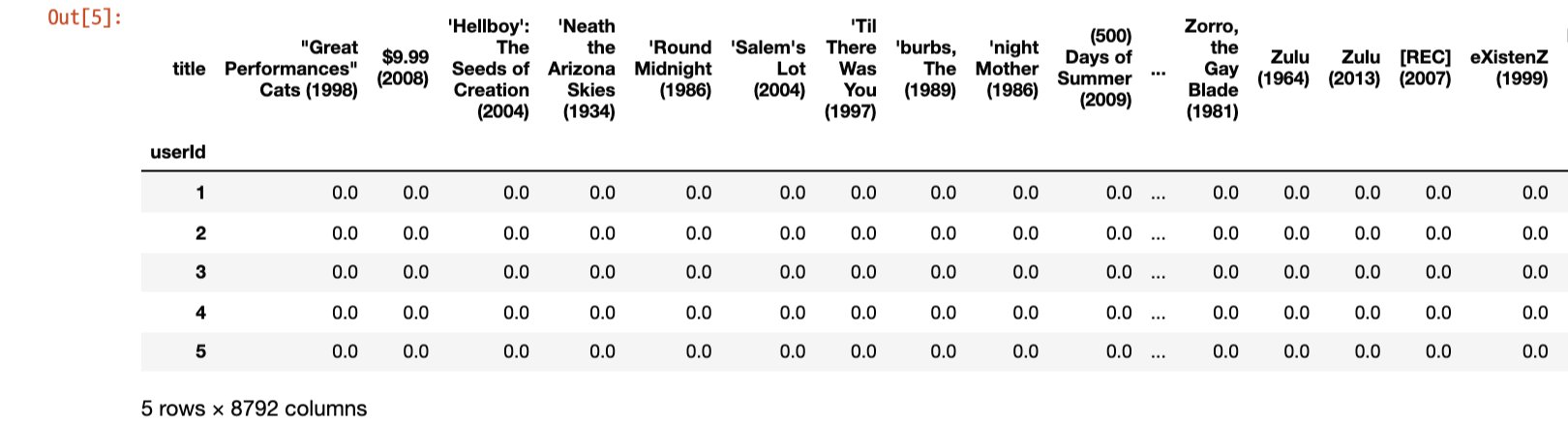
코사인 유사도 계산
# 사용자간 코사인 유사도 계산
from sklearn.metrics.pairwise import cosine_similarity
user_based = cosine_similarity(df_matrix_user)
# 데이터프레임화
user_based = pd.DataFrame(data=user_based, index=df_matrix_user.index, columns=df_matrix_user.index)
2. 영화 추천 서비스 구현
# 별점 비교와 정렬을 위해 reset index
df_matrix_movie_2 = df_matrix_movie.reset_index()코사인 유사도 기반 user와 별점 상황이 비슷한(취향이 비슷한) 유저 n명 반환
def get_similar_users(user, n):
return user_based[user].sort_values(ascending=False)[:n]추천을 원하는 사용자(user)가 이미 본 영화 제거
def del_watched_movie(user, n):
# user: 추천을 원하는 사용자
# n: 유사도가 높은 사용자
return df_matrix_movie_2[df_matrix_movie_2[user]==0][['title', user, n]]영화 추천 (유사도가 높은 사용자가 높게 별점을 준 영화)
def recommend_movie_by_user(user):
# 자기 자신 제외 유사도 높은 사용자 리스트 (3명)
users = get_similar_users(user, 4).index[1:4]
rcmd_movies = []
for i in users:
# 이미 본 영화 제외
# 유사도가 높은 사용자가 높게 별점을 준 영화 리스트 받아옴
movie_list = list(del_watched_movie(user, i).sort_values(i, ascending=False).title[:5])
rcmd_movies.append(movie_list)
return rcmd_movies
예) 사용자 3번에게 영화 추천
recommed_by_user(3)
user_num = int(input('추천을 원하는 사용자 번호를 입력하세요: '))
recommend_movie_by_user(user_num)
++) 고객들의 별점 분포에 따른 영화 유사도 측정
# 영화 기준 pivot table
df_matrix_movie = df.pivot_table(index='title', columns='userId', values='rating')
# 결측치 0으로 채움
df_matrix_movie.fillna(0, inplace=True)
# 영화간의 코사인 유사도 계산
movie_based = cosine_similarity(df_matrix_movie)
movie_based = pd.DataFrame(data=movie_based, index=df_matrix_movie.index, columns=df_matrix_movie.index)
영화간의 코사인 유사도를 이용한 영화 추천
def recommend_movie_by_rating(title):
return movie_based[title].sort_values(ascending=False)[:5]
예) 영화 'Godfather, The (1972)'와 유사한 영화 추천
recommend_movie_by_rating('Godfather, The (1972)')
별점 예측 모델
1. 데이터 전처리
1-1. movei_metadata

metadata_origin = metadata.copy() # 원본 데이터 유지
# feature select
# 청불 여부, 장르, 제목, 예산, 언어, 줄거리, 유명도, 제작사, 제작 국가, 상영시간, 평균 별점, 별점 수 등
meta_columns = ['id', 'title', 'adult', 'budget', 'original_language', 'popularity', 'production_companies', 'production_countries', 'runtime','vote_average', 'vote_count']
metadata = metadata[meta_columns]# production_companies
def get_production_com(s):
try:
result = eval(s)[0]['name']
except:
return -1 # [] 예외처리
return result
metadata['production_companies'] = metadata['production_companies'].apply(get_production_com)# production_countries
def get_production_country(s):
try:
result = eval(s)[0]['iso_3166_1']
except:
return -1 # [] 예외처리
return result
metadata['production_countries'] = metadata['production_countries'].apply(get_production_country)-1로 예외처리한 행 삭제
metadata = metadata[(metadata.production_countries != -1) & (metadata.production_countries != -1)]
1-2. links & metadata
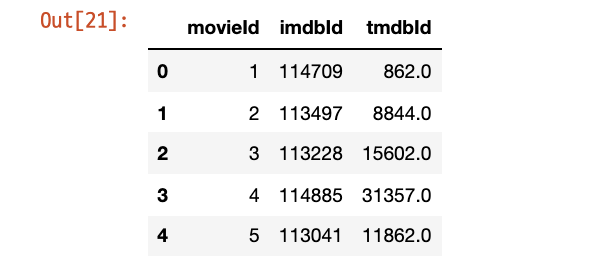

metadata.id = metadata.id.apply(lambda x: int(x)) # id -> int
# metadata 기준 merge
links_metadata = pd.merge(metadata[meta_columns], links, left_on = 'id', right_on='tmdbId', how='left')
del links_metadata['tmdbId'] # id = tmdbId
# reset index
links_metadata.reset_index(drop=True)
1-3. ratings

* 가장 별점 데이터가 많은 사용자 선택하여 해당 사용자에 대한 에측모델 생성
# 사용자 리스트
user_list = list(set(ratings['userId']))
# 사용자별 별점 수 리스트
counts = []
for id in user_list:
counts.append(len(ratings[ratings.userId == id]))
rating_counts = pd.DataFrame({'userId':user_list, 'counts':counts})
rating_counts[rating_counts.counts == max(counts)]
→ 2391건의 별점 데이터가 있는 547 번 사용자로 선택
# 별점을 가장 많이 준 사용자 547의 별점 데이터만 선택
rating_usr = ratings[ratings.userId == 547][['movieId', 'rating']]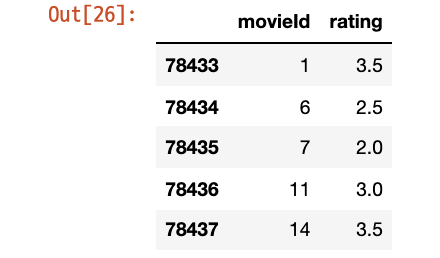
1-4. ratings & links_metadata


df = pd.merge(rating_usr, links_metadata, on='movieId')
2. 모델링 전처리
2-1. x 데이터
X_data = df.copy()
x_columns = ['rating', 'adult', 'budget', 'original_language', 'popularity', 'runtime', 'vote_average', 'vote_count']
X_data = X_data[x_columns]
del X_data['adult'] # 모든 행의 adult == False
# original language -> one hot vector
lang_df = pd.get_dummies(X_data['original_language'], prefix='lang')
X_data = X_data.join(lang_df)
del X_data['original_language']
사실 language 카테고리가 10개가 넘어가길래 귀찮아서 그냥 바로 one-hot vector로 전환하였다. 그냥 카테고리를 숫자로 바꿔서 해볼껄 하는 아쉬움이 조금 있다. 아예 unique 값을 데이터프레임으로 만들어서 바로 인덱스에 매칭시켜 숫자로 바꿨으면 편하게 할 수 있었을 것 같다. 근데 모.. 성능에는 크게 영향을 안줄거같긴 하다..
2-2. y 데이터
y_data = X_data[['rating']]
del X_data['rating']
++)
X_data.info()
object 타입의 feature들을 float형으로 바꿔주었다.
# object -> float
X_data.budget = X_data.budget.apply(lambda x: float(x))
X_data.popularity = X_data.popularity.apply(lambda x: float(x))
* 근데 한가지 이상한점 *
y_data2 = y_data.copy()
y_data2.rating = y_data2.rating.apply(lambda x: int(x*10))영화 별점의 분포가 0.5 부터 1.0, 1.5, 2.0, ... 4.5까지 0.5 단위로 float형으로 되어있다.
float형의 데이터로 학습과 예측은 잘 되는데 이상하게 accuracy를 계산하려하면 자꾸 y가 연속값이라며 값을 구할 수 없다고 나온다.
그럴꺼면 학습이나 예측도 되지 말던가,, 예측도 0.5 단위로 잘 나오면서.....
혹시나해서 10을 곱해서 모두 정수로 만들고 해보니 잘 나온다..
이유는 아직도 모르겠다.
나중에 시간될 때 강사님께 한번 여쭤봐야겠다!
* 해결 *
2021.07.12 - [python/k-digital] - [K-DIGITAL] mid-project-1. 영화 별점 데이터 분석(추가) - 분류모델의 성능 향상
[K-DIGITAL] mid-project-1. 영화 별점 데이터 분석(추가) - 분류모델의 성능 향상
멋쟁이사자처럼 X K-DIGITAL Training - 07.12 [github] https://github.com/ijo0r98/likelion-kdigital/tree/main/mid-project-1 ijo0r98/likelion-kdigital 멋쟁이사자처럼 & K-DIGITAL. Contribute to ijo0r98..
juran-devblog.tistory.com
3. train / test split
# train / test
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X_data, y_data2, test_size=0.3, random_state=0)
4. 모델 생성
4-1. XGBoost
from xgboost import XGBClassifier
# create model
model = XGBClassifier(seed = 0, n_jobs = -1, learning_rate = 0.1, n_estimators = 100, max_depth = 3)
# fit
model.fit(x_train, y_train)
from sklearn.metrics import accuracy_score
y_pred = model.predict(x_test)
accuracy_score(y_test, y_pred)>> 0.26504297994269344
너무 낮아서 당황했지만,, 침착하게 다시,,
4-2. RandomForest
from sklearn.ensemble import RandomForestClassifier
# create model
clf = RandomForestClassifier(n_estimators=13)
# fit
clf.fit(x_train, y_train)
from sklearn.metrics import accuracy_score
y_pred = clf.predict(x_test)
clf.score(x_test, y_test)>> 0.22492836676217765
... ^^
4-3. Hyper-parameter Optimization
그나마 accuray가 높던 XGBoost HPO
from sklearn.model_selection import GridSearchCV
xgb = XGBClassifier()
param_grid = {'max_depth': [3, 5, 7],
'learning_rate': [0.01, 0.1, 0.2, 0,3],
'subsample': [0.6, 0.8, 1.0]}
# param_grid = {
# 'silent': [False],
# 'max_depth': [3, 5, 7],
# 'learning_rate': [0.01, 0.1, 0.2, 0,3],
# 'min_child_weight': [1.0, 3.0, 5.0, 7.0, 10.0],
# 'n_estimators': [100]}
grid = GridSearchCV(xgb, param_grid, refit=True, verbose=1)
grid.fit(x_train, y_train)
print('The best parameters are ', grid.best_params_)>> The best parameters are {'learning_rate': 0.01, 'max_depth': 3, 'subsample': 0.6}
params = {'learning_rate': 0.01, 'max_depth': 3, 'subsample': 0.6}
xgb = XGBClassifier(**params)
xgb.fit(x_train, y_train)
accuracy_score(y_test, xgb.predict(x_test))>> 0.2707736389684814
예측 모델은 처참히 실패..😱
프로젝트 리뷰
아직 끝나진 않았지만 간단히 적어보는 미드프로젝트1 후기
왜이렇게 accuracy가 낮은지 고민해보니 일단 데이터 양이 너무 적은 것 같다.
2000건이면 그래도 좀 괜찮지않나? 싶었는데 머신러닝하기에는 너어어어어무 턱없이 부족한 양인것 같다.
그리고 타겟에 영향을 미치는 x를 내가 임의로 정한거라 더 정확도가 떨어지는 것 같다.
장르 데이터를 좀 유용하게 쓰고싶었는데 하나의 영화에 여러 장르가 섞여있는 경우가 많아서 어떻게 처리할지 고민하다가 관뒀다.
생각해보니 language가 아니라 genre야 말로 one-hot vector처리해서 x데이터에 포함시켰으면 좋았을 것 같다고 방금 생각했다..!
내일이 발표날이라 시간이 될지 모르겠지만 시간이 된다면 한번 해봐야겠다.
그 외에도 다른 팀원분들은 metadata를 활용하여 영화 평균 별점에 영향을 미치는 요인들을 분석하고 평균 별점 예측 모델을 만든다던지 아니면 웹 크롤링을 이용하여 추천 영화의 포스터를 가져와 보여준다던지 등등 다양한 작업들을 하셨다.
보면서 내 코드에도 적용해보고하며 배우고 있는 중이다.
팀플 정말.. 내가 공부하며 부족했던 부분도 깨닫고 다른 팀원들에게 배우기도 많이 배우고 정말 유익한 시간이다 ^_^
근데..... 강사님........ 이제 팀플 그만.... 2주 넘게 팀플 하는거 넘나 힘들고 기가 쏙 빨린다구용....
한달 쪼금 넘었는데 벌써 팀플 3개째라니.... 힝..
728x90
'PYTHON > K-DIGITAL' 카테고리의 다른 글
| [K-DIGITAL] 머신러닝을 넘어 딥러닝으로 (0) | 2021.07.14 |
|---|---|
| [K-DIGITAL] 미드프로젝트. 영화 별점 데이터 분석(추가) - 분류모델의 성능 향상 (0) | 2021.07.12 |
| [K-DIGITAL] 세미프로젝트2. 타이타닉 생존자 예측 모델 만들기(2) (0) | 2021.07.06 |
| [K-DIGITAL] 텍스트데이터 분석 TF-IDF과 유사도 계산 (0) | 2021.07.06 |
| [K-DIGITAL] 세미프로젝트2. 타이타닉 생존자 예측 모델 만들기(1) (0) | 2021.07.05 |
댓글 영역