고정 헤더 영역
상세 컨텐츠
본문
728x90
멋쟁이사자처럼 X K-DIGITAL Training - 06.11
TF-IDF (Term Frequency - Inverse Document Frequency)
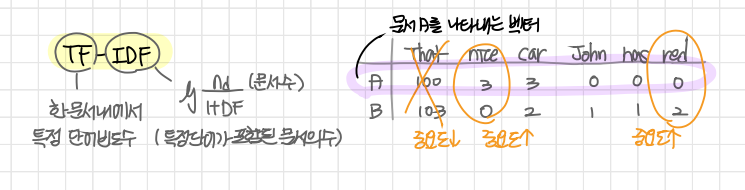
- TF (단어 빈도, term frequency)
특정 단어가 문서 내에 얼마나 자주 등장하는지 나타내는 값 - DF (문서 빈도, document fequency)
다른 문서에서 특정 단어가 얼마나 자주 등장하는지 나타내는 값, 특정 단어를 가진 문서의 수- 여러 문서가 있을 때 하나의 문서에서만이 아니라 여러 문서에서 자주 등장하는 단어일 경우 중요도가 낮아짐
- 하나의 문서에서만 많이 나오고 다른 문서에서 적게 등장할 경우 그 문서에서 해당 단어의 중요도가 높음을 알 수 있음
- IDF (역문서 빈도, inverse document frequency)
DF의 역수 - TF-IDF
TF와 IDF를 곱한 값
점수가 높은 단어일수록 다른 문서에는 많지 않고(IDF가 작고) 해당 문서에서 자주 등장하는(TF가 높은) 단어임을 의미
sklearn 라이브러리
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vectorizer = TfidfVectorizer()
# 벡터화
tfidf_matrix = tfidf_vectorizer.fit_transform([doc1, doc2]).todense()
tfidf1 = tfidf_matrix[0]
tfidf2 = tfidf_matrix[1]* todense()
fit_transform의 결과로 만들어지는 행렬은 회소행렬(spare matrix)
회소행렬 내에는 무수히 많은 0이 존재하는데 이는 메모리 낭비로 이어짐
todense()를 통해 0인 값을 아예 제외하고 나머지 숫자만 실제로 저장하는 방식으로 처리하게됨
이렇게 나온 결과가 바로 dense matrix -> numpy array 형태로 만들어짐
텍스트 유사도 구하기
1. 자카드 유사도 (Jacard Similarity)
두 문장(문자열 텍스트)을 각각 단어의 집합으로 만든 뒤 유사도 측정
두 집합의 교집합을 두 집합의 합집합으로 나눠줌
(* tf-idf 벡터 사용x)
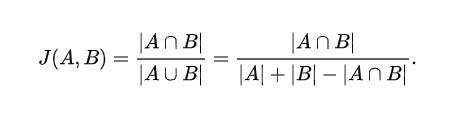
1) 각각 단어를 추출하여 각각의 단어 집합으로 만든다.
2) 두 집합의 교집합인 공통된 단어의 개수를 구한다.
3) 2번에서 구한 개수를 두 집합의 합집합의 개수(전체 단어 수)로 나눈다.
4) 결과값은 0~1 사이로 나올 것이다.
→ 1에 가까울수록 서로 유사도가 높다는 의미
2. 코사인 유사도 (Cosine Similarity)
from sklearn.metrics.pairwise import cosine_similarity
cosine_similarity(tfidf1, tfidf2)두 벡터값 사이 코사인 각도
-1(유사하지 않음) ~ 1(완전히 동일) 사이 값을 가짐
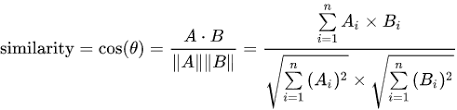
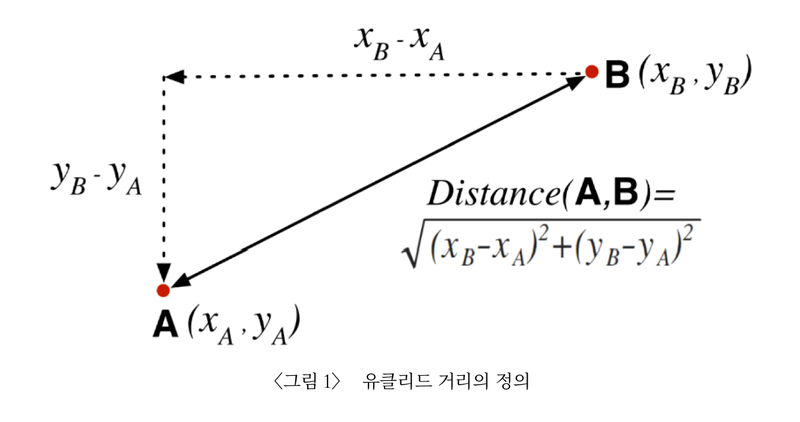
3. 유클리디안 유사도 (Euclidean Distance, L2-Distance)
from sklearn.metrics.pairwise import euclideen_distance
euclideen_distance(tfidf1, tfidf2)가장 기본적인 거리를 측정하는 유사도 공식
유클리디언 거리란 좌표공간에서의 두 점 사이의 거리로 tf-idf로 구한 벡터 사이의 거리 계산하여 구함
최소 0에서 무한대로 늘어날 수 있으며 거리가 가까울수록(0일수록) 유사도가 크고 값이 클수록 유사도가 작음
++ 추가)
유클리디안 거리는 거리 기반 - 좌표를 기반으로 가까운 좌표에 있는 점들이 유사도가 높다. (* 차원 축소 기법 PCA등과 자주 조합되어 사용)
코사인 유사도는 기울기 기반 - 기울기와 방향이 같은 벡터가 유사도가 높다고 축정
→ 코사인 유사도는 2차원보다 높은 차원의 데이터, 벡터의 크기가 중요하지 않은 데이터에 주로 사용
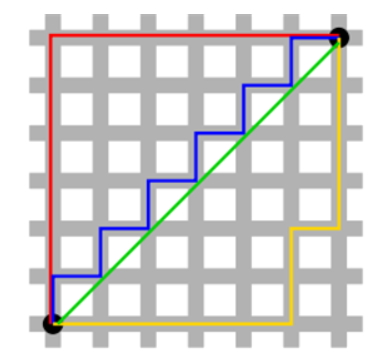
4. 멘하탄 유사도 (Manhattan Similarity)
from sklearn.metrics.pairwise import manhattan_distances
manhattan_distances(tfidf1, tfidf2)멘하탄 거리를 통해 유사도 측정
멘하탄 거리란 사각형 격자로 이뤄진 공간에서 출발점에서 도착점까지 도달할 수 있는 최단거리 구하는 개념
오직 수평, 수직 이동만 하여 최단 거리 계산
++ 실습) 영화 [쇼생크 탈출], [인셉션], [대부] 사이 유사도 계산
라이브러리
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity텍스트 데이터(영화 리뷰) 준비
with open('data/shawshank.txt', 'r', encoding = 'utf-8') as f:
doc1 = ''
lines = f.readlines()
for line in lines:
doc1 += line
with open('data/godfather.txt', 'r', encoding= 'utf-8') as f:
doc2 = ''
lines = f.readlines()
for line in lines:
doc2 += line
with open('data/inception.txt', 'r', encoding= 'utf-8') as f:
doc3 = ''
lines = f.readlines()
for line in lines:
doc3 += linetf-idf 벡터 생성
corpus = [doc1, doc2, doc3]
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(corpus).todense()코사인 유사도 계산
print("[쇼생크 탈출] & [대부] : ", cosine_similarity(X[0], X[1]))
print("[쇼생크 탈출] & [인셉션] : ", cosine_similarity(X[0], X[2]))
print("[대부] & [인셉션] : ", cosine_similarity(X[1], X[2]))>> [쇼생크 탈출] & [대부] : [[0.93484399]]
[쇼생크 탈출] & [인셉션] : [[0.18080469]]
[대부] & [인셉션] : [[0.16267018]]
728x90
'PYTHON > K-DIGITAL' 카테고리의 다른 글
| [K-DIGITAL] 미드프로젝트. 영화 별점 데이터 분석 (0) | 2021.07.10 |
|---|---|
| [K-DIGITAL] 세미프로젝트2. 타이타닉 생존자 예측 모델 만들기(2) (0) | 2021.07.06 |
| [K-DIGITAL] 세미프로젝트2. 타이타닉 생존자 예측 모델 만들기(1) (0) | 2021.07.05 |
| [K-DIGITAL] 머신러닝 알고리즘(5) 스태킹 앙상블(Stacking Ensemble), vecstack 실습 (0) | 2021.07.01 |
| [K-DIGITAL] 머신러닝 알고리즘(4) KNN, K-means - sklearn 실습 (0) | 2021.07.01 |
댓글 영역