고정 헤더 영역
상세 컨텐츠
본문
728x90
멋쟁이사자처럼 X K-DIGITAL Training - 06.30
[참고] 모델 앙상블 2021.06.30 - [python/k-digital] - [K-DIGITAL] 머신러닝 알고리즘(3) 의사결정트리
[K-DIGITAL] 머신러닝 알고리즘(3) 의사결정트리
멋쟁이사자처럼 X K-DIGITAL Training - 06.29 [이전] 2021.06.29 - [python/k-digital] - [K-DIGITAL] 머신러닝 알고리즘(1) 회귀분석과 분류분석 [K-DIGITAL] 머신러닝 알고리즘(1) 회귀분석과 분류분석 멋쟁이..
juran-devblog.tistory.com
model ensemble (모델 앙상블)
주어진 데이터로 여러 서로 다른 예측 모형을 생성한 후 이 모델들의 예측 결과들을 종합하여 하나의 최종결과를 도출
- Bagging : 여러 모델에서 나온 값을 계산하여 최종 결과를 내는 방식 → 모델끼리 독립적이며 속도가 빠름
- Boosting : 모델1을 보완하여 모델 2에 가중치를 반영하고 다시 이를 보완하여 모델 3에 반영, 에러가 판단의 기준 → 성능이 좋음
Stacking Ensemble (스태킹 앙상블)
개별 모델이 예측한 데이터를 다시 training set으로 사용하여 학습
여러 모델을 활용하여 각각의 예측 결과를 도출한 뒤 그 예측 결과를 결합해 최종 예측 결과를 만들어내는 것
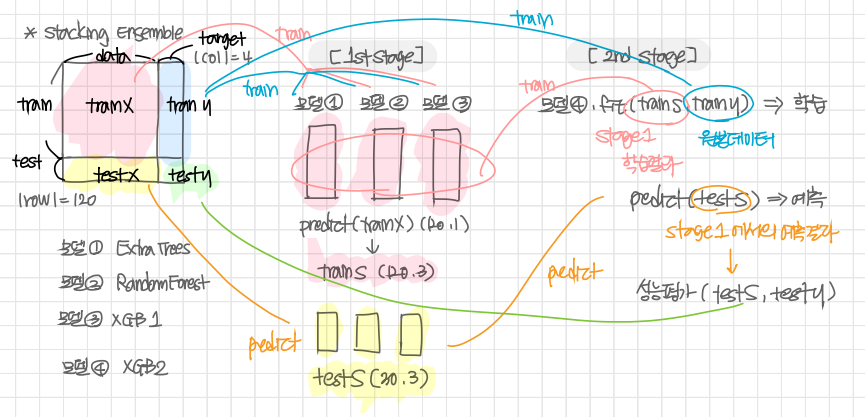
단계 1) n개의 모델이 원본 데이터(train_x, train_y)로 학습을 거친 뒤 새로운 학습 데이터셋(train_s) 생성
각각 학습된 모델로 테스트 데이터셋(test_s) 생성
단계 2) 단계 1에서 나온 학습 데이터(train_s)와 원본 타겟 데이터(train_y)로 학습
이전에 나온 테스트 데이터셋(test_s)과 원본 테스트데이터 타겟(test_y)으로 성능 평가
++ 실습)
1. Functional API (stacking)
라이브러리
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier # !conda install py-xgboost
from vecstack import stacking # # !pip install vecstack==0.4.0vecstack.stacking stacking을 위한 패키지
Stage 0.
- 데이터 준비
iris = load_iris()
X, y = iris.data, iris.target
# 원본데이터 train / test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)- 모델 준비
models = [
ExtraTreesClassifier(random_state = 0, n_jobs = -1, n_estimators = 100, max_depth = 3),
RandomForestClassifier(random_state = 0, n_jobs = -1, n_estimators = 100, max_depth = 3),
XGBClassifier(seed = 0, n_jobs = -1, learning_rate = 0.1, n_estimators = 100, max_depth = 3)]
Stage 1. 각각의 모델 학습 후 새로운 train, test 데이터 생성
S_train, S_test = stacking(models,
X_train, y_train, X_test, # (120, 3), (120, 1), (30, 3)
regression = False,
metric = accuracy_score,
n_folds = 4, stratified = True, shuffle = True,
random_state = 0, verbose = 2) .
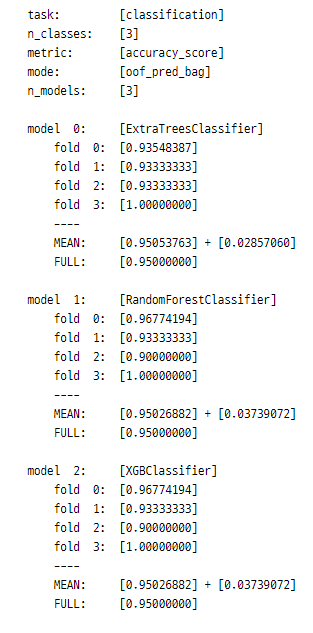
Stage 2. 이전에 생성한 학습 데이터로 새로운 모델 학습
- 모델 생성
model = XGBClassifier(seed = 0, n_jobs = -1, learning_rate = 0.1, n_estimators = 100, max_depth = 3) - 모델 학습
model = model.fit(S_train, y_train) - 예측
y_pred = model.predict(S_test)>> y_pred (예측값)
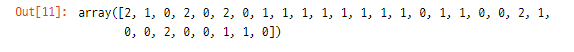
y_test (실제값)
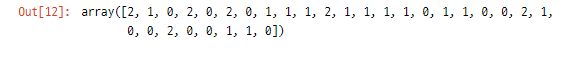
- 성능
print('Final prediction score: [%.8f]' % accuracy_score(y_test, y_pred))>> Final prediction score: [0.96666667]
2. Scikit-Learn API (StackingTransformer)
라이브러리 추가
from vecstack import StackingTransformerStage 0.
- 데이터 준비
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)- 모델 준비
estimators = [
('ExtraTrees', ExtraTreesClassifier(random_state = 0, n_jobs = -1, n_estimators = 100, max_depth = 3)),
('RandomForest', RandomForestClassifier(random_state = 0, n_jobs = -1, n_estimators = 100, max_depth = 3)),
('XGB', XGBClassifier(seed = 0, n_jobs = -1, learning_rate = 0.1, n_estimators = 100, max_depth = 3))]Stage 1.
stack = StackingTransformer(estimators,
# X_train, y_train, X_test
regression = False,
metric = accuracy_score,
n_folds = 4, stratified = True, shuffle = True,
random_state = 0, verbose = 2)
stack = stack.fit(X_train, y_train)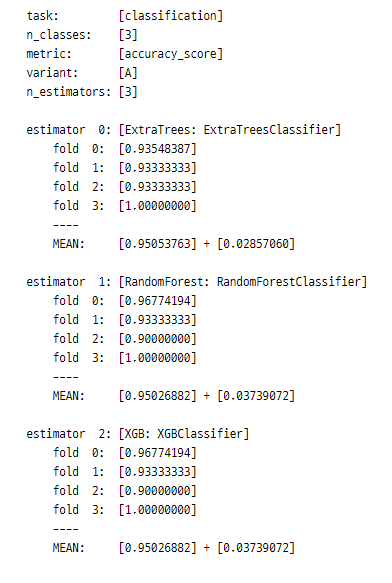
S_train = stack.transform(X_train)
S_test = stack.transform(X_test)
Stage 2.
model = XGBClassifier(seed = 0, n_jobs = -1, learning_rate = 0.1, n_estimators = 100, max_depth = 3)
model = model.fit(S_train, y_train) - 예측
y_pred = model.predict(S_test) - 성능
print('Final prediction score: [%.8f]' % accuracy_score(y_test, y_pred))>> Final prediction score: [0.96666667]
728x90
'PYTHON > K-DIGITAL' 카테고리의 다른 글
| [K-DIGITAL] 텍스트데이터 분석 TF-IDF과 유사도 계산 (0) | 2021.07.06 |
|---|---|
| [K-DIGITAL] 세미프로젝트2. 타이타닉 생존자 예측 모델 만들기(1) (0) | 2021.07.05 |
| [K-DIGITAL] 머신러닝 알고리즘(4) KNN, K-means - sklearn 실습 (0) | 2021.07.01 |
| [K-DIGITAL] 머신러닝 알고리즘(4) KNN, K-MEANS, PCA (0) | 2021.07.01 |
| [K-DIGITAL] 분류 성능에 대한 측정 ROC Curve와 AUC (0) | 2021.07.01 |
댓글 영역