고정 헤더 영역
상세 컨텐츠
본문
728x90
멋쟁이사자처럼 X K-DIGITAL Training - 06.29
[이전]
2021.06.29 - [python/k-digital] - [K-DIGITAL] 머신러닝 알고리즘(1) 회귀분석과 분류분석
[K-DIGITAL] 머신러닝 알고리즘(1) 회귀분석과 분류분석
멋쟁이사자처럼 X K-DIGITAL Training - 06.25 지도 학습 (Supervised Learning) 훈련 데이터로부터 하나의 함수를 유추해내기 위한 기계학습 인간 개입에 의한 분석 방법 입력 데이터에 대한 정답인 종속 변
juran-devblog.tistory.com
2021.06.30 - [python/k-digital] - [K-DIGITAL] 머신러닝 알고리즘(2) SVM
[K-DIGITAL] 머신러닝 알고리즘(2) SVM
멋쟁이사자처럼 X K-DIGITAL Training - 06.29 [이전] 2021.06.29 - [python/k-digital] - [K-DIGITAL] 머신러닝 알고리즘(1) 회귀분석과 분류분석 [K-DIGITAL] 머신러닝 알고리즘(1) 회귀분석과 분류분석 멋쟁이..
juran-devblog.tistory.com
지도학습 > 의사결정트리 (결정트리 학습법, Decision Tree)
분류와 회귀 모두 가능한 지도 학습 모델
특정 기준에 따라 데이터를 구분하는 모델인 결정 트리 모델 생성
이해하기 쉽고 해석이 용이하나 입력 데이터의 작은 변동에도 트리 구성이 크게 달라질 수 있음 (과적합)

- root node : 초기지점, 맨 처음 노드
- terminal node(leaf node) : 가장 마지막 노드
model ensemble (모델 앙상블)
주어진 데이터로 여러 서로 다른 예측 모형을 생성한 후 이 모델들의 예측 결과들을 종합하여 하나의 최종결과를 도출
- Bagging : 여러 모델에서 나온 값을 계산하여 최종 결과를 내는 방식 → 모델끼리 독립적이며 속도가 빠름
- Boosting : 모델1을 보완하여 모델 2에 가중치를 반영하고 다시 이를 보완하여 모델 3에 반영, 에러가 판단의 기준 → 성능이 좋음
XG Boost (Extreme Gradient Boosting)
의사결정나무의 단점을 해결하기 위해 Boosting기법 (model ensemble 기법중 하나) 적용
적당한 학습만 한 후 (과적합 방지) 여러 버전으로 트리를 생성하여 여러 예측 결과를 가지고 분류 선택
1) Boosted Decision Tree
weak learner을 strong learner로 변환시키는 알고리즘 - 약한 학습기를 여러개 사용하여 하나의 강건한 학습기를 만들어냄
이를 위해 각각의 예측을 혼합 - regression(회귀) 분석에서는 평균이나 가중평균, classification(분류) 분석에서는 투표 방식 이용
- weak learner : 무작위로 선정하는 것보다 성공 확률이 높은 (오차율이 50% 이하인) 학습규칙
- strong learner : weak learner를 하나로 모아서 만든 더 좋은 예측율을 갖는 규칙
2) AdaBoost (Adaptive Boosting)
데이터를 바탕으로 여러 weak learner들 반복적으로 생성하고 앞선 learner가 잘못 예측한 데이터에 가중치를 부여하여 학습 (boosting)
최종적으로 만들어진 strong learner 이용하여 실제 예측 진행
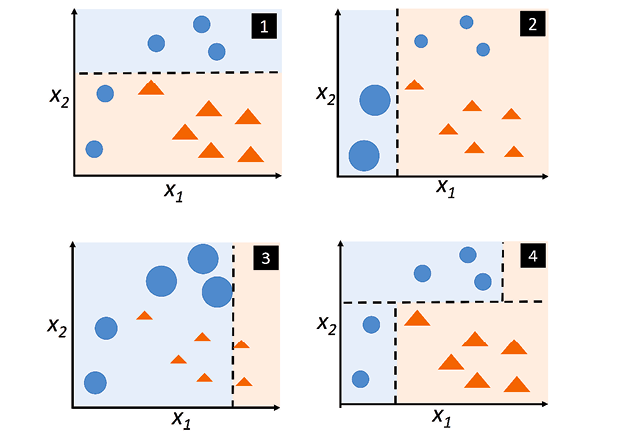
3) Gradient Boosing
경사 하강법을 적용, 가중치를 최적화하여 AdaBoost보다 성능을 개선한 Boosting 기법
학습 성능은 좋으나 모델의 학습시간이 오래 걸리는 단점 발생
4) XG Boost (Extreme Gradient Boosting)
병렬 처리 기법을 적용하여 Gradient Boosting보다 학습 속도를 크게 끌어올림
트리를 구성할 때 트리의 노드에서 어떤 특성으로 가지를 쳐야할 지 결정하는 과정 중 예측값 계산에 병렬 처리 사용
Random Forest (랜덤 포레스트)

의사결정트리에 Bagging 기법을 적용한 앙상블 머신러닝 모델
여러 결정 트리를 형성하고 각 트리 통과 결과, 가장 많이 득표한 결과를 최종 분류 결과로 선택
일부 트리는 overfitting 될 수 있지만 많은 수의 트리를 생성함으로써 overfitting이 예측하는데 있어 큰 영향을 미치지 못하도록 방지
트리를 형성할 때 데이터셋에만 변화를 주는 것이 아니라 feature 선택도 함께 변화
feature 선택 시 기존에 존재하는 feature의 부분집합 활용
728x90
'PYTHON > K-DIGITAL' 카테고리의 다른 글
| [K-DIGITAL] 머신러닝 알고리즘(3) 의사결정트리 - sklearn 실습 (0) | 2021.06.30 |
|---|---|
| [K-DIGITAL] 머신러닝 알고리즘(2) SVM - sklearn 실습 (0) | 2021.06.30 |
| [K-DIGITAL] 머신러닝 알고리즘(2) SVM (0) | 2021.06.30 |
| [K-DIGITAL] 머신러닝 알고리즘(1) 회귀분석(선형, 로지스틱) - sklearn 실습 (0) | 2021.06.29 |
| [K-DIGITAL] 머신러닝 알고리즘(1) 회귀분석과 분류분석 (0) | 2021.06.29 |
댓글 영역