고정 헤더 영역
상세 컨텐츠
본문
728x90
멋쟁이사자처럼 X K-DIGITAL Training - 07.23
[GIT] https://github.com/ijo0r98/likelion-kdigital/tree/main/semi-project-3
GitHub - ijo0r98/likelion-kdigital: [국비교육] AI 인재 양성 프로그램
[국비교육] AI 인재 양성 프로그램. Contribute to ijo0r98/likelion-kdigital development by creating an account on GitHub.
github.com
주제
딥러닝까지 배우고 또다시 프로젝트가 시작되었다.
정형데이터를 주로 사용하길 권장하셨고 캐글과 이곳저곳을 둘러본 결과.. 우리 팀은 DACON에 나온 공모전에 나가기로 결정하였다..!
배운 내용들을 실제로 적용해보고 이왕이면 공모전에서도 좋은 결과를 얻었으면 좋겠는데.. 배운지 한달된 실력으로 될지는 모르겠다.
[DACON] https://dacon.io/competitions/official/235745/overview/description
주차수요 예측 AI 경진대회
출처 : DACON - Data Science Competition
dacon.io

단지코드가 붙은 아파트 단지마다 총 세대수, 전용 면적, 면적별 세대수, 임대료 등등의 정보가 주어진다.
이런 정보들을 통해 해당 단지에 주차 자리가 얼마나 필요할지 등록 차량 수를 예측하는 것이다.
데이터는 train/test csv파일이 주어지며 train 데이터로 학습시킨 뒤 test 데이터를 예측에 사용하고 그 예측지들을 제출하여 평가받는다.
평가 지표는 MAE (Mean Absolute Error) 이며 제출하는 즉시 바로 점수가 계산된다.
데이터 둘러보기
train.csv
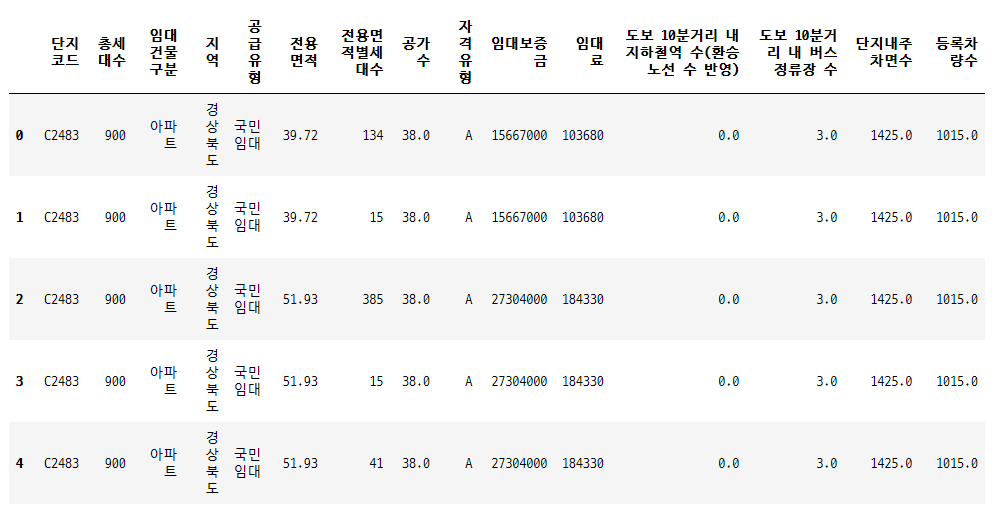
등록차량수가 우리가 예측해야할 값(y)
test.csv

test 데이터의 경우 등록차량수(y)가 없다. 우리는 이 값을 예측해야한다!
하지만 데이터에 문제가 있다.

주최측에서 올린 데이터 오류와 우리가 적용한 해결방안을 정리해보자면
1. 한 단지코드에 대해 전용면적별 세대수 합계와 총세대수가 일치하지 않는 경우
-> 전용면적별 세대수 합계와 총 세대수 사이 차이를 전용면적별 세대수 기준 가중치를 주어 전용면적별 세대수에 더해줌, 그 합을 맞춰줌
2. 동일한 단지에 단지코드가 2개로 부여된 경우
3. 단지코드 등 기입 실수로 데이터 정제 과정에서 매칭 오류 발생
-> 2, 3번 오류에 해당하는 단지는 모두 제외시킴
그리고 하나의 단지코드 안에서도 건물 구분이라던지 전용 면적 등등이 달라 여러 행으로 나눠져 데이터가 구성되어 있었다.
결측치를 해결한 뒤 이러한 값들을 통일시켜 하나의 단지코드에 하나의 행만 오도록, 단지코드를 유니크 값으로 만들기 위한 전처리를 해주었다.
또한 대회에서 주어지는 인구 정보로는 조금 부족하다고 생각되어 다른 자료를 추가하였다.
[e-나라지표] 국토교통부 제공 2020년 12월 자동차 등록 현황.xlsx https://www.index.go.kr/potal/main/EachDtlPageDetail.do?idx_cd=1257
e-나라지표 지표조회상세
www.index.go.kr
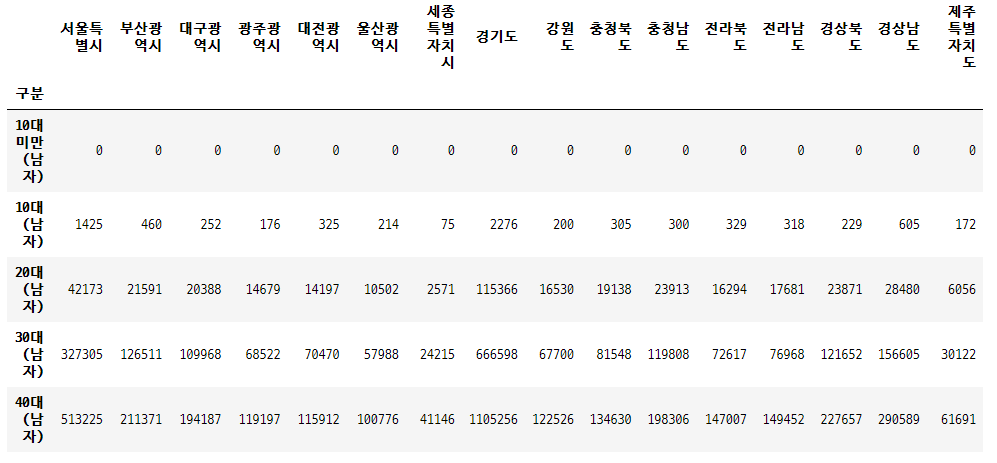
대회 제공 지역별 인구수 데이터 (age_gender_info.csv)

대회에서 주어지는 지역별 인구수 데이터와 위의 엑셀 데이터를 이용하여 지역별로 점수(numeric)를 부과하였다.
전처리 과정은 깃에서 확인 -> https://github.com/ijo0r98/likelion-kdigital/tree/main/semi-project-3
프로젝트를 진행하며 새로 배운 내용들과 처음 적용해본 라이브러리들(pipeline, hpo)을 기준으로 포스팅 할 계획이당
Pipeline (파이프라인)
Scikit-Learn은 전처리 기능에 일반적으로 사용되는 기능을 모두 내장하고 있다.
전처리 과정은 일반적으로 두 번 이상 적용하게 된다. 이때 정의한 전처리 과정의 재사용성을 높이고 편이성을 높이기 위해 파이프라인을 구성한다.
파이프라인을 사용하여 데이터 사전 처리뿐 아니라 모델 학습 등 반복적으로 필요한 단계들을 포함하는 단일 개체를 만들 수 있다.
라이브러리
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
우리는 train / test 데이터 모두에 one-hot encoding과 standard scaling이 필요하여 이를 하나의 파이프라인으로 만들고 모델에 학습시키기 전에 통과시켜주었다.
feature type 정리
# numeric
numeric_features = ['총세대수', '공가수', '도보 10분거리 내 지하철역 수(환승노선 수 반영)',
'도보 10분거리 내 버스정류장 수', '단지내주차면수', '평균면적', '평균임대보증금', '평균임대료', '국민임대A',
'국민임대B', '공공임대(50년)A', '영구임대C', '임대상가D', '영구임대E', '영구임대F', '국민임대E',
'국민임대G', '국민임대H', '공공임대(10년)A', '공공임대(분납)A', '장기전세A', '영구임대I', '공공분양D',
'영구임대A', '행복주택J', '행복주택K', '행복주택L', '공공임대(5년)A', '행복주택M', '행복주택N',
'행복주택O', '지역점수']
numeric_transformer = StandardScaler()
# categorical
categorical_features = ['임대건물구분', '지역']
categorical_transformer = OneHotEncoder(categories='auto',sparse = False)파이프라인 생성
# 전처리용 transformer 만들고, pipeline 생성
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
preprocessor_pipe = Pipeline(steps=[('preprocessor', preprocessor)])파이프라인 통과
preprocessor_pipe.fit(train)one-hot encoding시 생성되는 column 명 살리기
preprocessor.named_transformers_['cat'].get_feature_names(categorical_features)
feature_names_arr = np.array(numeric_features)
feature_names_arr = np.append(feature_names_arr, preprocessor.named_transformers_['cat'].get_feature_names(categorical_features) )파이프라인 통과
x_train = pd.DataFrame(preprocessor_pipe.transform(train), columns = feature_names_arr)
x_test = pd.DataFrame(preprocessor_pipe.transform(test), columns = feature_names_arr)* test 데이터는 '등록차량수(y) 컬럼이 없기 때문에 train 데이터와 feature 수가 다르다.
따라서 이렇게 실행하면

ValueError: X has 35 features, but ColumnTransformer is expecting 36 features as input.
이런 에러가 난다. (해당 에러메시지는 여러 방법으로 해결하려고 하던 중 발생한 오류라 숫자가 조금 다르지만 똑같은 에러)
말 그대로 파이프라인 구성 시 지정한 feautre 수와 입력된 데이터의 feature 수가 달라서 생기는 오류인 거 같은데 아무리 feature 수를 똑같이 맞춰줘도 test 데이터만 들어가면 저렇게 오류가 난다 ㅠㅡㅠ
근데 또 갑자기 어느순간 돌아가져서 그냥 그렇게 만들어진 csv 파일을 받아서 모델 학습에 사용하였다.
잘 모르겠지만 다른 팀원분이 강사님께 여쭤보니 예전 파이프라인은 들어오는 열의 수와 파이프라인의 열의 수가 달라도 그냥 넘겼다고 한다. 근데 버전이 높아지면서? 그 오류를 잡아낸다고 하셨나 암튼 그랬던 것 같다.
지금 보니 fit(train)이 문제가 되는거 같기도 하고.. 이 부분에 대해서는 시간이 더 이상 없어 고치지 못했지만 조금더 알아볼 필요가 있는 것 같ㄷㅏ,,
AutoML (자동화 머신러닝)
라이브러리
from hyperopt import fmin, tpe, hp, anneal, Trials
from sklearn.model_selection import KFold, cross_val_score
from sklearn.externals import joblib # 모델 저장에 사용하는 라이브러리hyperot Baysian Optimization 기반 하이퍼파라미터 튜닝 라이브러리
Cat Boost, XGBoost, NGBoost 대상 HPO 적용
# 교차검증
random_state = 0
kf = KFold(n_splits=10, random_state=0)
def gb_mae_cv_CAT(params, random_state=0, cv=kf, x = xx_train, y= yy_train) :
params = {'n_estimators': int(params['n_estimators']),
'learning_rate': params['learning_rate']}
CAT_HPO = CatBoostRegressor(random_state=random_state,**params)
CAT_score = -cross_val_score(CAT_HPO, x, y, cv=cv, scoring="neg_mean_absolute_error", n_jobs=-1).mean()
return CAT_score
def gb_mae_cv_XGB(params, random_state=0, cv=kf, x = xx_train, y= yy_train) :
params = {'n_estimators': int(params['n_estimators']),
'learning_rate': params['learning_rate']}
XGB_HPO = XGBRegressor(random_state=random_state,**params)
XGB_score = -cross_val_score(XGB_HPO, x, y, cv=cv, scoring="neg_mean_absolute_error", n_jobs=-1).mean()
return XGB_score
def gb_mae_cv_NGB(params, random_state=0, cv=kf, x = xx_train, y= yy_train) :
params = {'n_estimators': int(params['n_estimators']),
'learning_rate': params['learning_rate']}
NGB_HPO = NGBRegressor(random_state=random_state,**params)
NGB_score = -cross_val_score(NGB_HPO, x, y, cv=cv, scoring="neg_mean_absolute_error", n_jobs=-1).mean()
return NGB_scorespace={'n_estimators': hp.quniform('n_estimators', 100, 2000, 1),
'learning_rate': hp.loguniform('learning_rate', -5, 0)
}
space_XGB={'n_estimators': hp.quniform('n_estimators', 100, 2000, 1),
'max_depth' : hp.quniform('max_depth', 1,20,1),
'learning_rate': hp.loguniform('learning_rate', -5, 0)
}
trials_CAT = Trials()
trials_XGB = Trials()
trials_NGB = Trials()- CAT Boost
best_CAT=fmin(fn=gb_mae_cv_CAT, # function to optimize
space=space,
algo=tpe.suggest, # optimization algorithm, hyperotp will select its parameters automatically
#Tree of Parzen Estimators (TPE)
#http://hyperopt.github.io/hyperopt/
max_evals=50, # maximum number of iterations
trials=trials_CAT, # logging
rstate=np.random.RandomState(0) # fixing random state for the reproducibility
)
CAT_best_reg = CatBoostRegressor(learning_rate = best_CAT['learning_rate']
,n_estimators = int(best_CAT['n_estimators']))
CAT_fitted_model = CAT_best_reg.fit(xx_train, yy_train)
joblib.dump(CAT_fitted_model, 'CAT_fitted_model.pkl', compress =True) # 모델 저장
tpe_results_CAT=np.array([[x['result']['loss'],
x['misc']['vals']['learning_rate'][0],
x['misc']['vals']['n_estimators'][0]] for x in trials_CAT.trials])
tpe_results_CAT_df=pd.DataFrame(tpe_results_CAT,
columns=['score', 'learning_rate', 'n_estimators'])
tpe_results_CAT_df.plot(subplots=True,figsize=(10, 10))- XGBoost
best_XGB=fmin(fn=gb_mae_cv_XGB,
space=space_XGB,
algo=tpe.suggest,
max_evals=50,
trials=trials_XGB,
rstate=np.random.RandomState(0)
)
XGB_best_reg = XGBRegressor(learning_rate = best_XGB['learning_rate']
,max_depth = int(best_XGB['max_depth'])
,n_estimators = int(best_XGB['n_estimators']))
XGB_fitted_model = XGB_best_reg.fit(xx_train, yy_train)
joblib.dump(XGB_fitted_model, 'XGB_fitted_model.pkl', compress =True) # 모델 저장
tpe_results_XGB=np.array([[x['result']['loss'],
x['misc']['vals']['learning_rate'][0],
x['misc']['vals']['n_estimators'][0]] for x in trials_XGB.trials])
tpe_results_XGB_df=pd.DataFrame(tpe_results_XGB,
columns=['score', 'learning_rate', 'n_estimators'])
tpe_results_XGB_df.plot(subplots=True,figsize=(10, 10))- NGBoost (Natural Gradient Boost)
best_NGB=fmin(fn=gb_mae_cv_NGB,
space=space,
algo=tpe.suggest,
max_evals=50,
trials=trials_NGB,
rstate=np.random.RandomState(0)
)
NGB_best_reg = NGBRegressor(learning_rate = best_NGB['learning_rate']
,n_estimators = int(best_NGB['n_estimators']))
NGB_fitted_model=NGB_best_reg.fit(xx_train, yy_train)
joblib.dump(NGB_fitted_model, 'NGB_fitted_model.pkl', compress =True) # 모델 저장
tpe_results_NGB=np.array([[
x['misc']['vals']['learning_rate'][0],
x['misc']['vals']['n_estimators'][0]] for x in trials_NGB.trials])
tpe_results_NGB_df=pd.DataFrame(tpe_results_NGB,
columns=[ 'learning_rate', 'n_estimators'])
tpe_results_NGB_df.plot(subplots=True,figsize=(10, 10))
사실 코드는 잘 모르겠다.. 너무 오래 걸려서 실행도 해보지 못했다..!
일단 결과를 비교해보자면
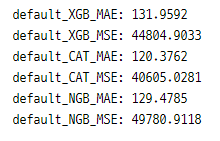
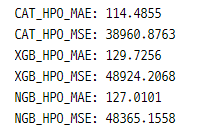
성능이 조금 더 좋아진 모습을 볼 수 있으며 CatBoost의 성능이 가장 좋아졌음을 알 수 있다 (수업 중 들은 내용으로는 가장 최근에 나온 알고리즘이라고 한당)
Feature Importance
이건 사실 이건 차트 색상이 이뻐서 가져왔따
import seaborn as sns
# NGB 기준
feature_importance_values = NGB_reg.feature_importances_[0]
# Top 중요도로 정렬하고, 쉽게 시각화하기 위해 Series 변환
feature_importances = pd.Series(feature_importance_values, index=xx_train.columns)
# 중요도값 순으로 Series를 정렬
feature_top20 = feature_importances.sort_values(ascending=False)[1:21]
plt.figure(figsize=[8, 6])
plt.title('Feature Importances')
sns.barplot(x=feature_top20, y=feature_top20.index)
plt.show()
Git에 빠져있는 해석부분을 채워보자면
역시 단지 내 총 세대수(인원수, 공가수)의 영향을 가장 많이 받음을 알 수 있고 임대료와 보증금의 경우도 중요한 요인임을 알 수 있었다.
임대료와 임대 보증금이 세대의 경제적 지표를 의미한다고 할 수 있지 않을까 생각이 된다.
현재 one-hot encoding을 거쳤기 때문에 여러 지역이 그래프에 나와있는데 numeric 컬럼이였던 지역 점수보다도 도보 10분거리 내 버스정류장수와 지하철역 수가 더 높은 순위를 차지하는 것을 보아 지역적 특색보다는 지역의 교통 인프라가 더 중요한 요소임을 알 수 있다.
Deep Learning 딥러닝 적용
간단히 머신러닝 적용 후 딥러닝을 적용해 보았다.
강사님께서는 데이터가 적기 때문에 딥러닝보다 머신러닝이 성능이 더 좋을수도 있을거라고 하셨다.
라이브러리
import tensorflow as tf
from tensorflow.keras import datasets, utils
from tensorflow.keras import models, layers, activations, initializers, losses, optimizers, metrics
인공신경망 생성
model = models.Sequential()
model.add(layers.Dense(input_dim=50, units=96, activation=None, kernel_initializer=initializers.he_uniform())) # he-uniform initialization
model.add(layers.Activation('relu')) # elu, relu / layers.ELU, layers.LeakyReLU
model.add(layers.Dense(units=32, activation=None, kernel_initializer=initializers.he_uniform()))
model.add(layers.Activation('relu'))
model.add(layers.Dense(units=32, activation=None, kernel_initializer=initializers.he_uniform()))
model.add(layers.Activation('relu'))
model.add(layers.Dense(units=32, activation=None, kernel_initializer=initializers.he_uniform()))
model.add(layers.Activation('relu'))
# dropout
model.add(layers.Dropout(rate=0.4))
model.add(layers.Dense(units=1, activation='linear'))모델 준비
model.compile(optimizer=optimizers.Adam(),
loss=losses.mean_absolute_error, # 평가지표 MAE
metrics=[metrics.mae])모델 학습
history = model.fit(xx_train, yy_train, batch_size=100, epochs=1000, validation_split=0.3, verbose=0)MAE 그래프
# loss curve func
def plot_loss_curve(total_epoch=10, start=1):
plt.figure(figsize=(15, 5))
plt.plot(range(start, total_epoch +1), history.history['loss'][start-1:total_epoch], label='Train')
plt.plot(range(start, total_epoch +1), history.history['val_loss'][start-1:total_epoch], label='Validation')
plt.xlabel('Epochs')
plt.ylabel('mae')
plt.legend()
plt.show()
plot_loss_curve(total_epoch=1000, start=1)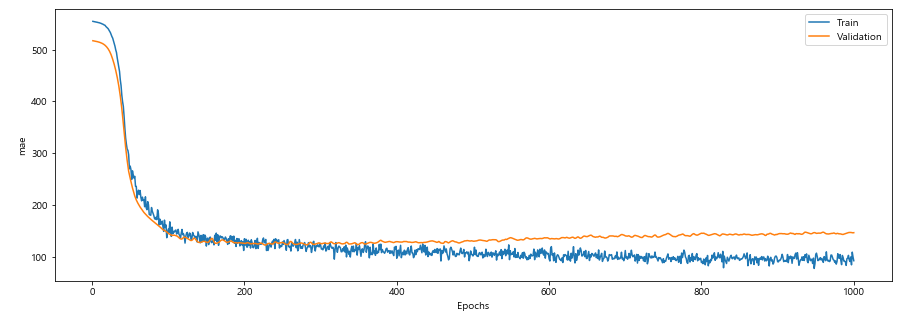
model.evaluate(xx_test,yy_test)>> 124/124 [==============================] - 0s 138us/sample - loss: 161.202 - mean_absolute_error: 161.2025
Keras Tuner (colab 이용)
라이브러리
# pip install -q -U keras-tuner
import tensorflow as tf
tf.compat.v1.logging.set_verbosity(tf.compat.v1.logging.ERROR)
from tensorflow import keras
from tensorflow.keras import layers
from keras import initializers
import kerastuner as kt
import IPython
def build_hyper_model(hp):
model = keras.Sequential()
# 첫번째 layer는 지정
model.add(layers.Dense(input_dim=xx_train.shape[1], units=64, activation=None, kernel_initializer=initializers.he_uniform()))
# layer 수의 범우 1~3
for i in range(hp.Int('num_layers', min_value=1, max_value=3)):
hp_units = hp.Int('units_' + str(i), min_value=32, max_value=512, step=32) # 퍼셉트론 수
hp_activations = hp.Choice('activation_' + str(i), values=['relu', 'elu']) # 활성화함수 종류
model.add(layers.Dense(units = hp_units, activation = hp_activations))
model.add(layers.Dense(1, activation=None))
# learning rate 최적화
hp_learning_rate = hp.Choice('learning_rate', values = [1e-2, 1e-3, 1e-4])
model.compile(optimizer = keras.optimizers.Adam(learning_rate = hp_learning_rate),
loss = keras.losses.MeanSquaredError(),
metrics = [keras.metrics.MeanAbsoluteError()])
return modeltuner = kt.BayesianOptimization(build_hyper_model,
objective = 'val_mean_absolute_error', # 평가 지표
max_trials = 10,
directory = 'test_prac_dir',
project_name = 'Parking_lot')# best 3 model
tuner.search(xx_train, yy_train, epochs=10, validation_data = (xx_test, yy_test))
tuner.results_summary(num_trials=3)
최적의 모델 3개 저장
top3_models = tuner.get_best_hyperparameters(num_trials=3)
for idx, model in enumerate(top3_models):
print('Model performance rank :', idx+1)
print(model.values)
print()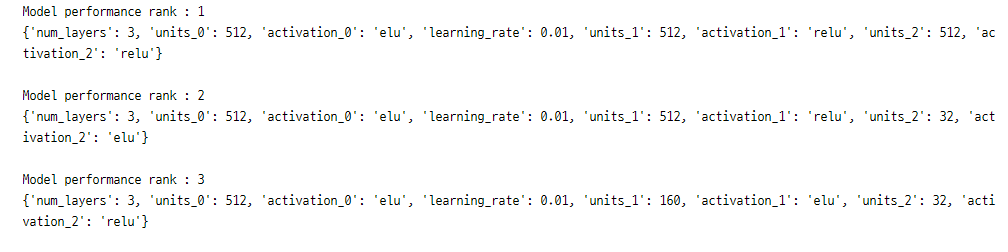
최적의 모델 파라미터 확인
best_hps = top3_models[0]
print("""
The hyperparameter search is complete.
* Optimal # of layers : {}
* Optimal value of the learning-rate : {}""".format(best_hps.get('num_layers'), best_hps.get('learning_rate')))
for layer_num in range(best_hps.get('num_layers')):
print('Layer {} - # of Perceptrons :'.format(layer_num), best_hps.get('units_' + str(layer_num)))
print('Layer {} - Applied activation function :'.format(layer_num), best_hps.get('activation_' + str(layer_num)))
최적의 모델 확인 2
models = tuner.get_best_models(num_models=3)
top_model = models[0]
top_model.summary()
print()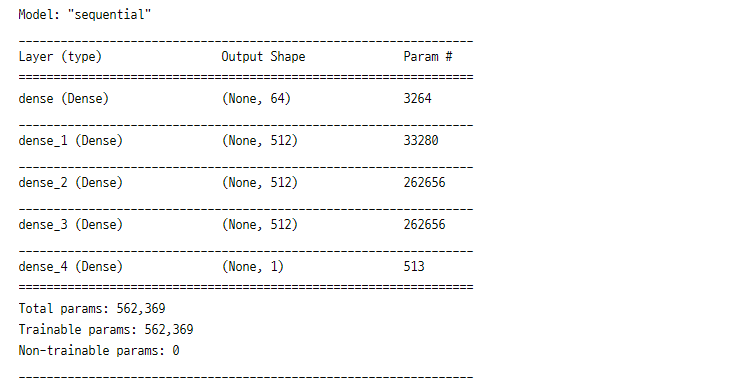
test 데이터에 대한 최적의 모델 성능 확인
results = top_model.evaluate(xx_test, yy_test)>> 4/4 [==============================] - 0s 3ms/step - loss: 29774.8613 - mean_absolute_error: 109.7835
[29774.861328125, 109.78351593017578]
++) 머신러닝 & 딥러닝 결과 비교
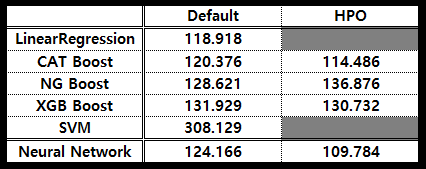
머신러닝이 가장 좋을것이라는 생각과 달리 HPO를 적용한 인공신경망 모델에서 가장 좋은 성능을 확인할 수 있었다.
세미프로젝트3을 마치고..
이번 프로젝트는 아쉬움이 많이 남는다.
일단 데이터 전처리 과정에서 너무 많은 시간이 흘러버렸다ㅠㅠ 처음 전처리 방향을 잘못잡아서 후반 모델링 성능 최적화에 더 시간을 쏟아부어야할때 다시 전처리를 진행하느라 정신이 너무 없었고 모델링에는 신경을 많이 쓰지 못했다.
또한 저번주에 수업 나간 딥러닝 알고리즘 자체에 대해서는 이해했지만 그 외의 HPO 등 다른 추가 학습자료에 대한 이해가 떨어지는 와중에 일단 되는대로 하고 다른 팀원분들 코드 따라가고 하다보니 조금 따라가지 못하는 감이 없지 않아 있었다.
다른 분들 얘기도 들어보니 역시나 나처럼 저번주 후반에 실습과 추가학습 자료에 대해 많이들 버거워하시는거 같았다 ㅠㅠ
갑자기 목요일부터 수업이 호다닥 나가더니 금요일에 후루룩 끝나고 팀플이 시작되서 쪼큼 당황스러웠다,,
그래도 팀원분들이 다들 열정넘치시고 잘하셔서 덕분에 잘 따라가고 성공적으로 팀플을 마무리할 수 있었다.
팀에 누가 되지 않기 위해 일주일동안 정말 머리싸매고 열심히 한거같다. 일주일동안 토익공부는 거의 못한듯 ,,
암튼 임대 주택과 관련 정책에 대한 지식을 더 쌓고 양이 적은 데이터 모델링의 방법과 HPO등을 더 열심히 봤다면 더 좋은 성능을 얻을 수 있었을 것 같은데 아쉬움이 너무 많이 남는다.
공모전 기간은 일주일정도 더 남긴 했는데 순위가 100위대라.. 더 해서 과연 순위권에 들 수 있을지는 모르겠다.
난 이제 지쳐서 모태..
그리고 내가 데이터분석과 딥러닝에 열심히 머리굴려본 결과....
난 데이터분석과는 좀 ,, ^^ 안맞는거같다 ^_^ 그냥 빨리 장고 배워서 웹개발 하고싶다..
중간에 그냥 관둘까, 괜히 수업 들었나, 쉅 듣지 말구 JPA랑 앱개발, 클라우드 공부나 더 할껄 하고 얼마나 후회를 많이 했는지 모르게따
한때 DBA가 되고싶었었으니 이런 데이터 다루는게 재밌을 줄 알았는데 개뿔 DBA와는 또 다른 느낌이다.
이제 장고 수업 듣고나면 드디어 마지막 파이널 프로젝트를 진행하게 될텐데 그때는 난 웹개발에 집중해 보고 싶다 !!!!
그리고 이제 데이터프레임으로 이뤄진 정형데이터 말구 이미지데이터 다루는 것도 해보고싶당 파이널때 주제 잘 골라야쥐
일단 그전에 금요일날 후후룩 나가서 멍때리고 들었던 CNN이랑 openCV쪽 복습부터 얼른 끝내놔야겠다..
정말 힘든 일주일이였다..
마지막으로 현재 DACON에서 우리 팀의 순위는
두구두구

발표할때 108위였는데 고새 더 떨어졌다 흐엉엉
728x90
'PYTHON > K-DIGITAL' 카테고리의 다른 글
| [K-DIGITAL] Django 실습과 pythonanywhere 배포(1) 웹 프로젝트 (0) | 2021.08.02 |
|---|---|
| [K-DIGITAL] 이미지 데이터 처리를 위한 CNN (0) | 2021.08.01 |
| [K-DIGITAL] sklearn / tf 모델 저장 & Keras Callbacks API (0) | 2021.07.16 |
| [K-DIGITAL] 딥러닝 Tensorflow2.x 실습 - MNIST (0) | 2021.07.16 |
| [K-DIGITAL] 딥러닝 Tensorflow1.x 실습 - MNIST (0) | 2021.07.15 |
댓글 영역