고정 헤더 영역
상세 컨텐츠
본문
728x90
드디어 마지막 프로젝트
이번 주제는 다른 팀원분께서 기획하고 준비하신 🍺맥주 추천 서비스🍺 이다
참고할 블로그도 준비해주셨는데 좋은 글이 많아 팀플을 하는데 큰 어려움없이 진행할 수 있었다.
데이터 크롤링부터 전처리, 유사도 기반 추천은 거의 비슷하게 따라갔고 그 외의 추천 알고리즘과 이미지 분석 등 다른 기능들을 추가하였다.
팀원분들 중 웹에 관심이 많으신 분들이 많아(나도 포함) 모델링이나 기능 구현은 빠르게 끝내고 웹 구성에 좀더 힘을 쓰고 있는 중이다.
사실 다른 팀원분들께서 평일과 주말에 많은 시간을 쏟아 기능 구현을 끝내주신 덕분에 수월하고 빠르게 진행중이다..!
토익만 아니였음 나도 힘을 더 쏟을 수 있었을텐데 아숩,,
이번에도 프로젝트를 준비하며 새로 배운 점과 짚어두면 좋을 점들 위주로 포스팅할 예정 ~.~
참고자료 & 깃
[참고 블로그] https://western-sky.tistory.com/54?category=847883 (이 분 블로그 덕이 크다🙇🏻♀️🙇🏻♀️)
맥주 추천시스템 구현 - 1. 데이터 크롤링
🍺 리뷰 데이터 크롤링 💡 어떤 맥주를 수집할 것인가? 추천시스템 구현을 위한 리뷰 데이터를 먼저 수집하려고 합니다. 맥주 데이터를 크롤링 할 곳은 RateBeer라는 전 세계 맥주 리뷰 사이트입
western-sky.tistory.com
이분도 티스토리 쓰시는데 다들 어디서 티스토리를 이렇게 이쁘게 꾸미는지.. 민경이도 이쁜 테마 했던데
난 기본 테마에 내 사진이랑 블로그 이름 글씨체 바꾼게 내 최대라구..
[데이터 수집] 맥주 데이터 수집 https://www.ratebeer.com/
https://www.ratebeer.com/
www.ratebeer.com
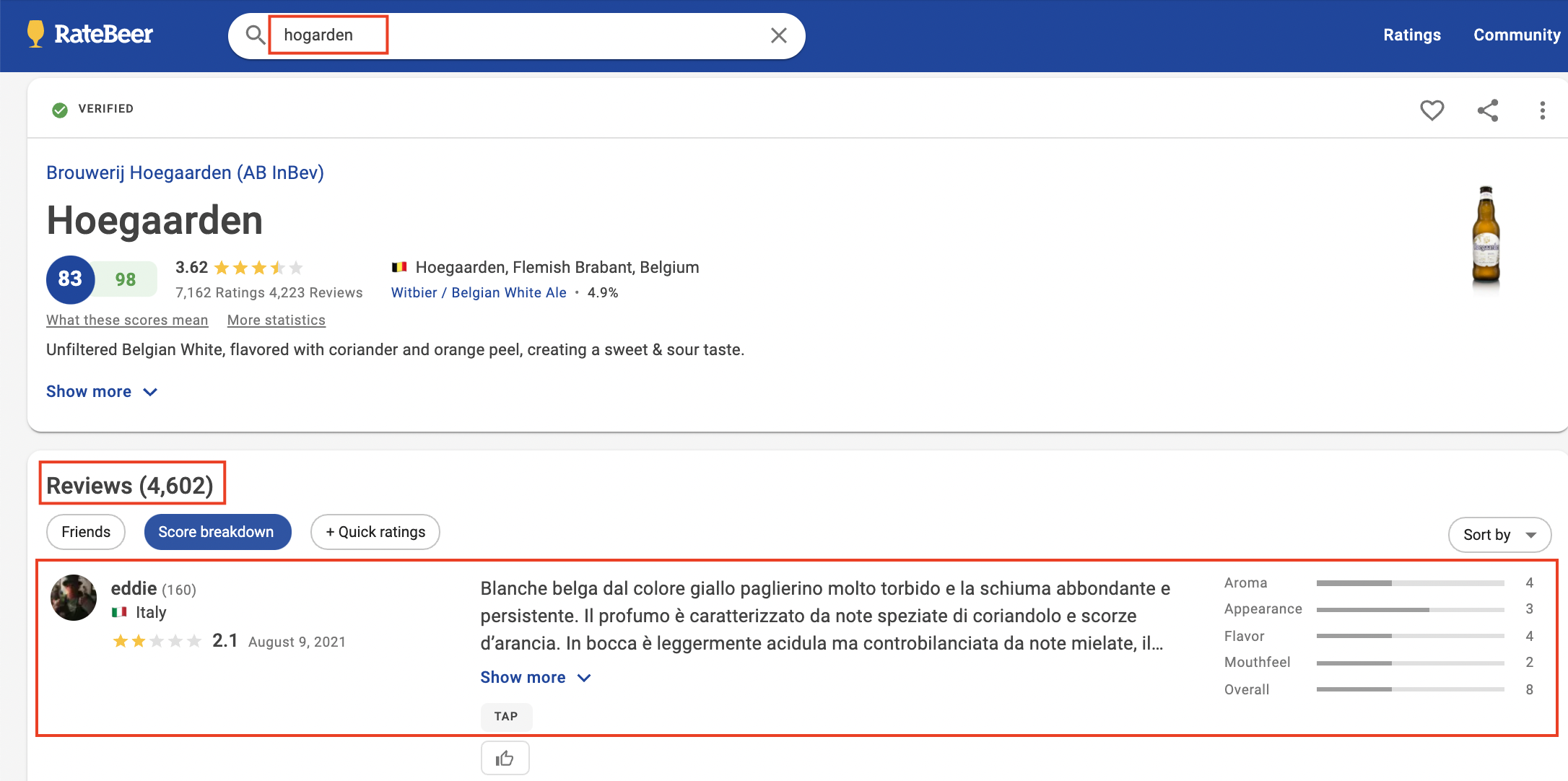
빨간색 상자가 크롤링에 사용한 부분
[GITHUB] https://github.com/ijo0r98/likelion-kdigital/tree/main/final-project
GitHub - ijo0r98/likelion-kdigital: [국비교육] AI 인재 양성 프로그램
[국비교육] AI 인재 양성 프로그램. Contribute to ijo0r98/likelion-kdigital development by creating an account on GitHub.
github.com
클러스터링
데이터 크롤링과 전처리 과정은 크게 중요한 부분 아님으로 생략 ..
전처리 후 맥주들의 정보를 가지고 클러스터링 진행
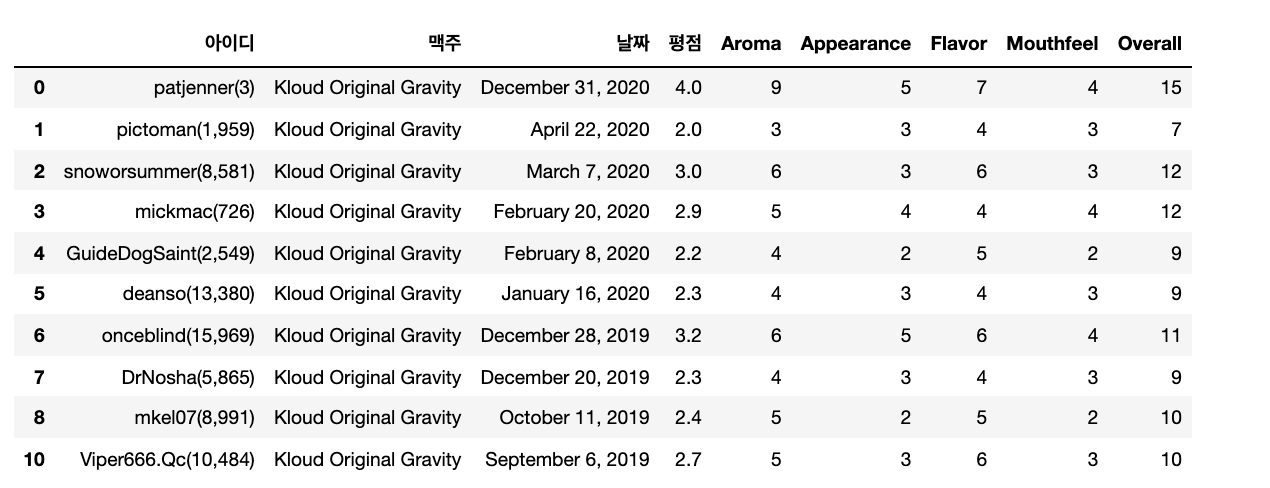
- 아이디: 리뷰를 남긴 사용자 아이디
- 맥주: 맥주명
- 날짜: 리뷰를 남긴 날짜
- 평점: 해당 맥주에 대한 전반적인 평점
- Aroma(향), Appearance(생김새), Flavor(맛), Mouthfeel(목넘김): 맥주 평가 요소들
- Overall: 평가 요소들의 점수 합
현재는 하나의 맥주에 대한 모든 사용자의 리뷰가 있는 상태임으로 각 맥주마다 평균 평점을 구하여 맥주를 유니크값으로 만들어 준다.
데이터프레임 생성, 평가 요소 컬럼 추가
tmp = data.copy()
tmp = tmp[['맥주']]
# 맥주 이름 중복행 제거
tmp.drop_duplicates(keep='first', inplace=True)
cols = ['Aroma','Appearance','Flavor','Mouthfeel','Overall']
# 5가지 요소 컬럼으로 추가
for col in cols:
tmp[col] = ''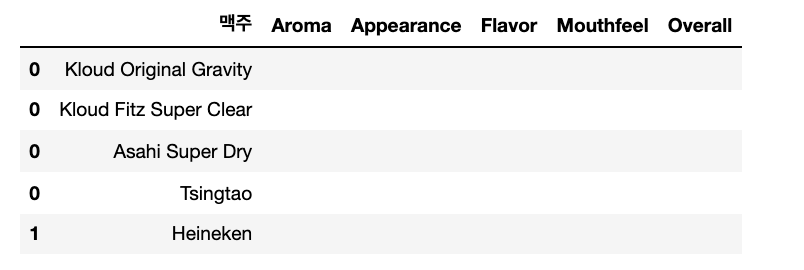
각 컬럼을 평균값으로 채워줌
for i in range(len(tmp)):
beer = tmp['맥주'].iloc[i]
length = len(data[data['맥주']==beer])
for col in cols:
col_sum = data[data['맥주']==beer][col].sum()
tmp[col].iloc[i] = col_sum/length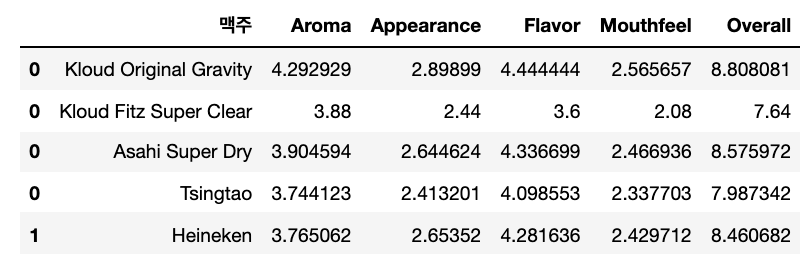
min-max scaling
from sklearn.preprocessing import StandardScaler, MinMaxScaler
beer_values = data[['Aroma','Appearance','Flavor','Mouthfeel', 'Overall']]
# scaling
scaler = MinMaxScaler()
scaler.fit(beer_values)
scaled = scaler.transform(beer_values)Elbow(엘보우)기법을 이용하여 최적의 클러스터 수 탐색
from sklearn import cluster
def elbow(X):
total_distance = []
for i in range(1, 11): # i: 클러스터 수, 1~10
model = cluster.KMeans(n_clusters=i, random_state=0)
model.fit(X)
print(model.inertia_)
total_distance.append(model.inertia_)
plt.plot(range(1, 11), total_distance, marker='o')
plt.xlabel('# of clusters')
plt.ylabel('Total distance (SSE)')
plt.show()
elbow(scaled)
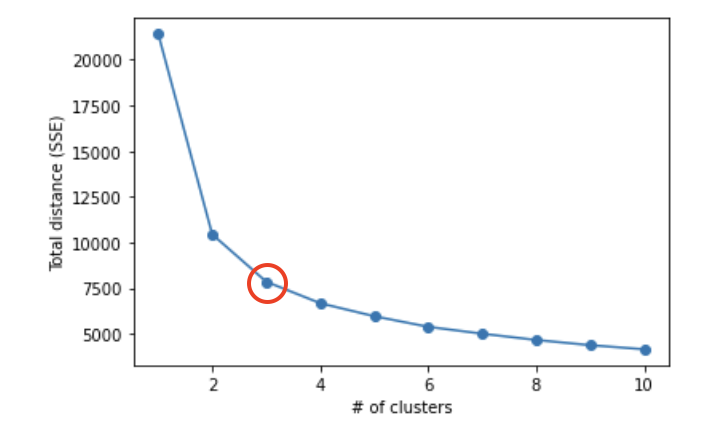
클러스터 수는 3개로 결정
[참고] 엘보우 기법 https://juran-devblog.tistory.com/105
[K-DIGITAL] 머신러닝 알고리즘(4) KNN, K-means - sklearn 실습
멋쟁이사자처럼 X K-DIGITAL Training - 06.30 [참고] 2021.07.01 - [python/k-digital] - [K-DIGITAL] 머신러닝 알고리즘(4) KNN, K-MEANS, PCA [K-DIGITAL] 머신러닝 알고리즘(4) KNN, K-MEANS, PCA 멋쟁이사자..
juran-devblog.tistory.com
모델 학습
from sklearn.cluster import KMeans
km = KMeans(n_clusters=3).fit(scaled)
km.cluster_centers_>> array([[0.67132212, 0.79917698, 0.7159419 , 0.71758944, 0.74625245],
[0.45290195, 0.52959519, 0.49099371, 0.46263676, 0.52549974],
[0.20304911, 0.27703949, 0.22959265, 0.21158257, 0.25799794]])
클러스터 결과 기존 데이터프레임에 연결
# 클러스터링 결과
predict = pd.DataFrame(km.predict(scaled))
predict.columns = ['Cluster']
# 평가 요소
scaled = pd.DataFrame(data=scaled, columns=['Aroma', 'Appearance', 'Flavor', 'Mouthfeel','Overall'])
# 맥주 이름
beer_names = data[['맥주']]
beer_names.reset_index(inplace=True, drop=True)
result = pd.concat([scaled, beer_names], axis=1).reset_index(drop=True)
result = pd.concat([result, predict], axis=1).reset_index(drop=True)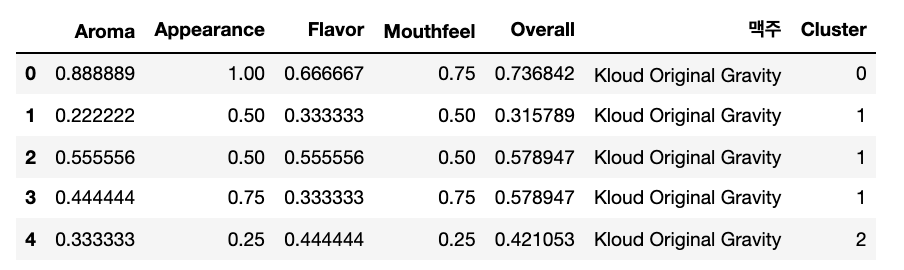
각 클러스터별 평균 점수 계산하여 데이터프레임화
cluster_result = km.cluster_centers_
cluster_result = pd.DataFrame(data=cluster_result)
cluster_result.columns = ['Aroma', 'Appearance', 'Flavor','Mouthfeel','Overall']
cluster_result.sort_values(by='Overall', inplace=True)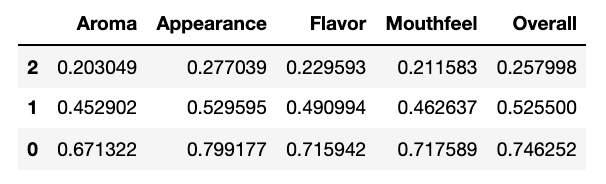
클러스터링 시각화
import plotly.express as px
import plotly.graph_objects as go
import plotly.io as podef show_cluster(result, name):
categories = ['Aroma', 'Appearance', 'Flavor','Mouthfeel', 'Overall']
color = ['skyblue', 'blue', 'salmon', 'green']
target = result[result['맥주'] == name]
cluster = target['Cluster'].iloc[0]
target = target[categories]
fig = go.Figure()
fig.add_trace(go.Scatterpolar(
r = c_result.values[0],
theta = categories,
fill='toself',
name='Soso',
line_color=color[0]
))
fig.add_trace(go.Scatterpolar(
r = c_result.values[1],
theta = categories,
fill='toself',
name='Sad',
line_color=color[1]
))
fig.add_trace(go.Scatterpolar(
r = c_result.values[2],
theta = categories,
fill='toself',
name='Good',
line_color=color[2]
))
fig.add_trace(go.Scatterpolar(
r = target.values[0],
theta = categories,
fill='toself',
name=name,
line_color=color[3]
))
fig.update_layout(
polar=dict(
radialaxis=dict(
visible=True,
)),
)
fig.show()show_cluster(result, 'Kloud Original Gravity')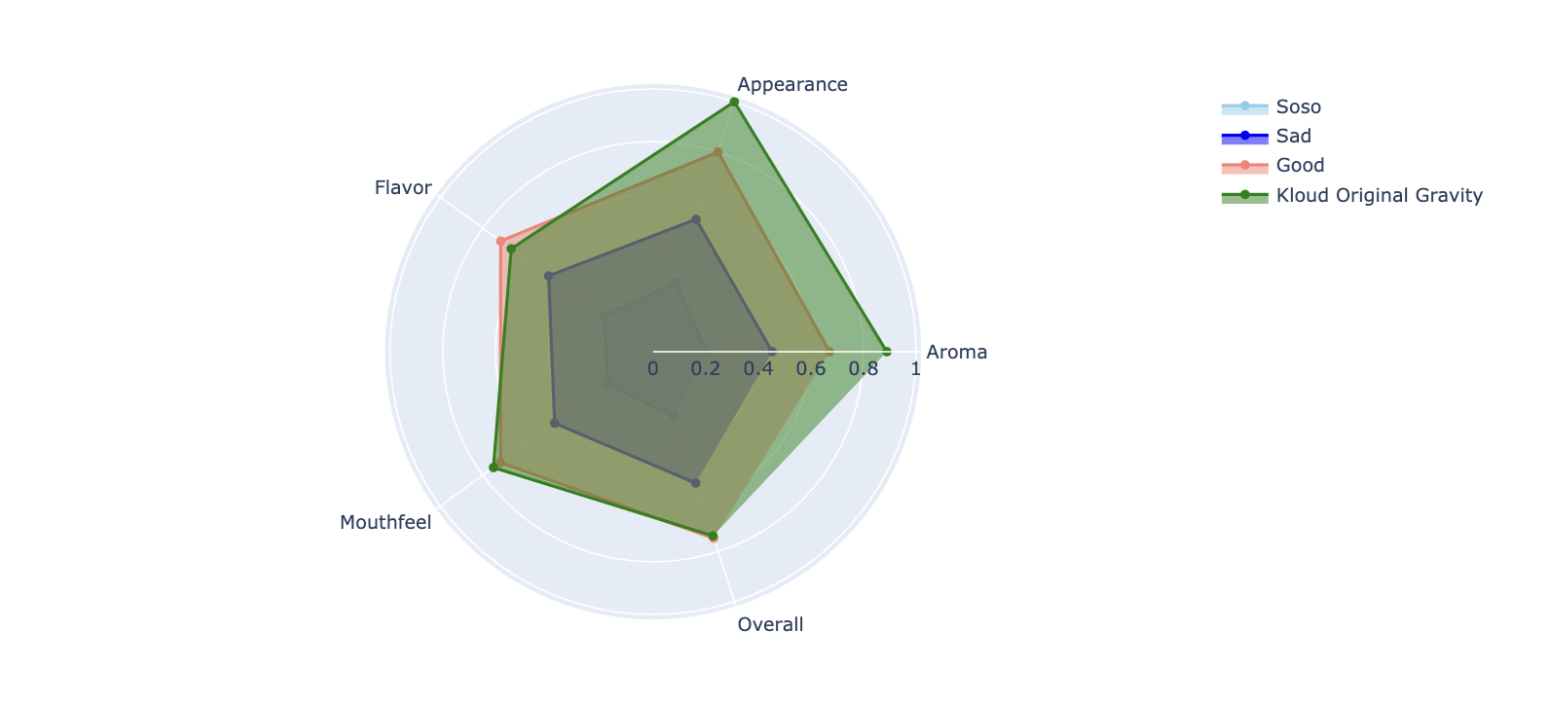
show_cluster(result, 'Kozel Černý (Dark) 10°')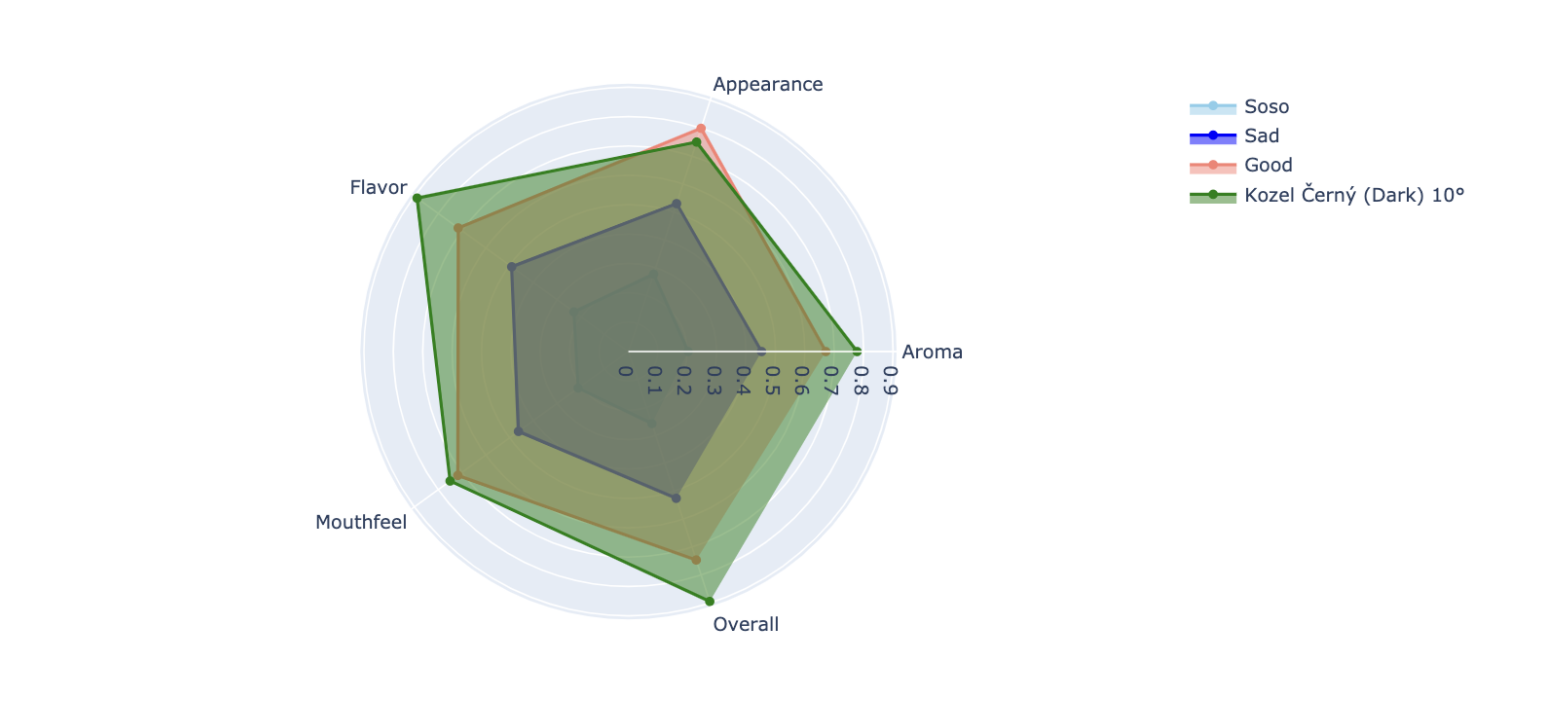
클러스터별 점수도 그렇고 블로그 글에서도 그렇고 왜 평가요소별 점수의 특징으로 클러스터링을 하지 않았을까 고민을 해보았다.
예를 들어 Aroma의 점수가 높은 그룹과 Mouthfleel의 점수가 유난히 낮은 그룹처럼 맥주의 특색이 보이도록 클러스터링을 하고싶었다.
하지만 여러번 시도해본 결과.. 클러스터링이 저렇게밖에 되지 않는다는걸 알았다 ㅠㅠ
보통 하나의 요소가 뛰어나게 높기보다는 전반적으로 모두 다 점수가 높거나 모든 요소가 점수가 다 낮거나 하는 경우밖에 없는 것 같다..
글쓴 분이 왜 시각화할때 클러스터의 라벨을 Soso, Sad, Good 이렇게 하였나 했더니 이런 이유 때문이였다..!
말 그대로 전반적으로 평점이 다 낮은 맥주 그룹과 중간 점수대의 맥주 그룹, 그리고 평점이 높은 맥주 그룹 이렇게로 나눠진다.
728x90
'PYTHON > K-DIGITAL' 카테고리의 다른 글
| [K-DIGITAL] 파이널프로젝트. BEERCRAFT 맥주 추천 서비스(4) openCV YOLO 이용한 이미지 분석 (0) | 2021.08.11 |
|---|---|
| [K-DIGITAL] 파이널프로젝트. BEERCRAFT 맥주 추천 서비스(2) 추천 시스템 (0) | 2021.08.10 |
| [K-DIGITAL] Django 실습과 pythonanywhere 배포(2) 서비스 배포 (0) | 2021.08.03 |
| [K-DIGITAL] Django 실습과 pythonanywhere 배포(1) 웹 프로젝트 (0) | 2021.08.02 |
| [K-DIGITAL] 이미지 데이터 처리를 위한 CNN (0) | 2021.08.01 |
댓글 영역