고정 헤더 영역
상세 컨텐츠
본문
728x90
[이전] 2021.08.09 - [python/mldl] - [K-DIGITAL] final-project. 맥주 추천 서비스(1) 데이터 수집부터 클러스터링까지
[K-DIGITAL] final-project. 맥주 추천 서비스(1) 데이터 수집부터 클러스터링까지
드디어 마지막 프로젝트 이번 주제는 다른 팀원분께서 기획하고 준비하신 🍺맥주 추천 서비스🍺 이다 참고할 블로그도 준비해주셨는데 좋은 글이 많아 팀플을 하는데 큰 어려움없이 진행할
juran-devblog.tistory.com
[GITHUB] https://github.com/ijo0r98/likelion-kdigital/tree/main/final-project > 2. 맥주 추천 시스템
GitHub - ijo0r98/likelion-kdigital: [국비교육] AI 인재 양성 프로그램
[국비교육] AI 인재 양성 프로그램. Contribute to ijo0r98/likelion-kdigital development by creating an account on GitHub.
github.com
[참고] 미드때 한 추천 알고리즘과 거의 유사함 2021.07.10 - [python/mldl] - [K-DIGITAL] mid-project. 영화 별점 데이터 분석
[K-DIGITAL] mid-project. 영화 별점 데이터 분석
멋쟁이사자처럼 X K-DIGITAL Training - 07.09 [github] https://github.com/ijo0r98/likelion-kdigital/tree/main/mid-project-1 ijo0r98/likelion-kdigital 멋쟁이사자처럼 & K-DIGITAL. Contribute to ijo0r98/..
juran-devblog.tistory.com
추천 알고리즘

http://www.kocca.kr/insight/vol05/vol05_04.pdf
1. Contents Based Filtering (컨텐츠 기반 필터링, CBF)
항목 자체를 분석하여 유사한 아이템 추천
컨텐츠 분석 / 유저 프로필 파악 / 유사 아이템 선택
항목을 분석한 프로파일(item profile)과 사용자의 선호도를 추출한 프로파일(user profile)을 추출하여 이의 유사성을 계산
(예로 들어 사용자가 '좋아요'를 누른 노래들의 음악적 특성과 사용자 프로파일을 비교하여 사용자가 선호할만한 음악 제공)
장점1) 다른 유저의 정보가 필요하지 않음
장점2) 개인의 독특한 취향 반영 가능
장점3) 새로운 아이템이나 대중적이지 않은 아이템도 추천 가능
한계) feature을 특정하기 어려운 아이템이 존재
알고리즘) TF-IDF, Word2Vec 등
2. Colloabrative Filtering (협업 필터링, CF)
많은 사용자들로부터 얻은 기호정보에 따라 사용자들의 관심사들을 자동적으로 예측하게 해주는 방법
기존 사용자 행동 정보를 분석하여 해당 사용자와 비슷한 성향의 사용자들이 기존에 좋아했던 항목을 추천
(예를 들어 '이 상품을 구매한 다른 사용자가 구매한 상품들' 추천 서비스)
최근접 이웃 기반 협업 필터링
유클리디안, 코사인, 피어슨, 자카드 등의 유사도 사용
user-based recommendation (사용자 기반 추천) : 나와 취향이 비슷한 다른 사용자가 선호하는 아이템 추천 (또는 사용자 그룹화)
item-based recommendation (아이템 기반 추천) : 내가 이전에 구매했던 이력을 기반으로 선호하는 아이템과 유사한 아이템 추천
* 현업에서는 아이템 기반 추천을 더 많이 사용
장점) feature을 선택하거나 구체적인 정보를 알 필요 없음
한계1) 신규 사용자의 경우 관찰된 행동 데이터가 없거나 적어서 추천의 정확도가 급격히 떨어지는 문제가 발생 (콜드스타트)
한계2) 매트릭스 분해 등 계산효율 저하
한계3) 비대칭적 쏠림 현상이나 관심 저조 항목의 정보 부족 문제 (롱테일 문제)
알고리즘) KNN, SGD, ALS 등
3. Hybrid Filtering (하이브리드 필터링)
두 알고리즘 모두 적용
Combining Filtering : 두 알고리즘 적용 후 가중평균 구함
Collaboration via Content : 평점 데이터와 아이템 프로필을 조합하여 사용자 프로필을 만들어 추천
데이터 전처리
리뷰수가 10건보다 적은 맥주 제외
def preprocessing(data, n):
min_id = data['아이디'].value_counts() >= n
min_id = min_id[min_id].index.to_list()
data = data[data['아이디'].isin(min_id)]
min_beer = data['맥주'].value_counts() >= n
min_beer = min_beer[min_beer].index.to_list()
data = data[data['맥주'].isin(min_beer)]
return data
for i in range(1,10):
data = preprocessing(data, 10)
print(data.shape)블로그에서 퍼왔지만 아직 이해 못한거 비밀
맥주간 유사도 기반 추천
1) 기준 맥주만 주어졌을 때
'평점' 컬럼으로 코사인 유사도 계산하여 기준이 되는 맥주와 유사한 맥주 추천
맥주 이름이 인덱스인 피벗 테이블 생성
beer_matrix = data.pivot_table(index='맥주', columns='아이디', values='평점')
beer_matrix.fillna(0, inplace=True)
위의 피벗테이블을 이용하여 맥주간 코사인 유사도 계산
from sklearn.metrics.pairwise import cosine_similarity
beer_similarity = cosine_similarity(beer_matrix)
beer_similarity = pd.DataFrame(data=beer_similarity, index=beer_matrix.index, columns=beer_matrix.index)
2) 기준이 될 맥주와 중요 항목이 주어졌을 때
중요하게 생각하는 항목의 코사인 유사도에 가중치를 부과, 이를 기반으로 기준 맥주와 유사한 맥주 추천
- Aroma(향)
- Flavor(풍미)
- Mouthfeel(목넘김)
# 가중치를 부과할 항목 가정
detail = 'Aroma'특정 항목 기준 코사인 유사도 계산하여 데이터프레임 반환
def recomm_feature(df, col):
feature = col
ratings = df[['아이디','맥주', feature]]
# 아이디가 인덱스인 피벗 테이블
id_matrix = data.pivot_table(index='아이디', columns='맥주', values=feature)
id_matrix = id_matrix.fillna(0)
# 맥주명이 인덱스인 피벗테이블
beer_matrix = id_matrix.transpose()
# 아이템-유저 매트릭스로부터 코사인 유사도 구하기
item_sim = cosine_similarity(beer_matrix, beer_matrix)
# cosine_similarity()로 반환된 넘파이 행렬에 맥주명을 매핑해 DataFrame으로 변환
item_sim_df = pd.DataFrame(data=item_sim, index=id_matrix.columns, columns=id_matrix.columns)
return item_sim_df각 항목별 코사인 유사도 계산
df_aroma = recomm_feature(data, 'Aroma')
df_flavor = recomm_feature(data, 'Flavor')
df_mouthfeel = recomm_feature(data, 'Mouthfeel')선택한 항목의 코사인 유사도에 가중치 부여
if detail=='Aroma':
beer_similarity_weighted = df_aroma * 0.8 + df_flavor * 0.1 + df_mouthfeel * 0.1
if detail=='Flavor':
beer_similarity_weighted = df_aroma * 0.1 + df_flavor * 0.8 + df_mouthfeel * 0.1
if detail=='Mouthfeel':
beer_similarity_weighted = df_aroma * 0.1 + df_flavor * 0.1 + df_mouthfeel * 0.8
3) 맥주 추천
def recommend_beer_by_cosine_similarity(df_sim, name):
return df_sim.loc[name].sort_values(ascending=False)[:5]
# 리스트로 반환
# return df_sim.loc[name].sort_values(ascending=False)[:5].index.tolist()# 가중치 부여 x
recommend_beer_by_cosine_similarity(beer_similarity, 'Asahi Super Dry')
# 가중치 부여
recommend_beer_by_cosine_similarity(beer_similarity_weighted, 'Asahi Super Dry')
사용자간 유사도 기반 추천
사용자 아이디가 인덱스인 피벗테이블 생성
# beer_similarity = cosine_similarity(beer_matrix)
# beer_similarity = pd.DataFrame(data=beer_similarity, index=beer_matrix.index, columns=beer_matrix.index)
id_matrix = beer_matrix.transpose()
사용자간 코사인 유사도 계산
from sklearn.metrics.pairwise import cosine_similarity
user_similarity = cosine_similarity(id_matrix)
user_similarity = pd.DataFrame(data=user_similarity, index=id_matrix.index, columns=id_matrix.index)
주어진 사용자와 비슷한 사용자 리스트 출력
def get_similar_users(name, n):
return user_similarity.loc[name].sort_values(ascending=False)[:n]username = '16erBlech'
get_similar_users(username, 5)
사용자가 마신 맥주 제외
tmp = beer_matrix.reset_index()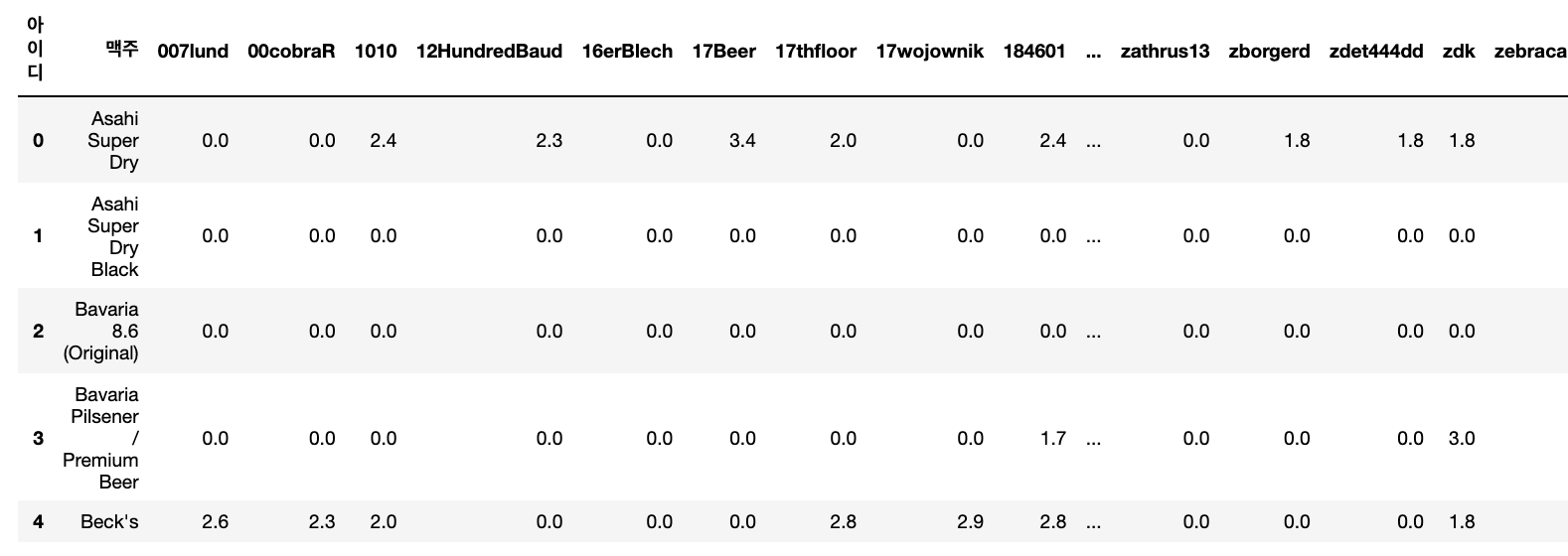
def del_rated_beer(df, user, i):
# user: 추천을 원하는 사용자
# i: 비슷한 취향을 가진 사용자
return df[df[user] == 0][['맥주', user, i]]# 00cobraR가 마셔본 맥주 리스트 중 16erBlech이 마시지 않은 맥주들
del_rated_beer(tmp, username, '00cobraR').head()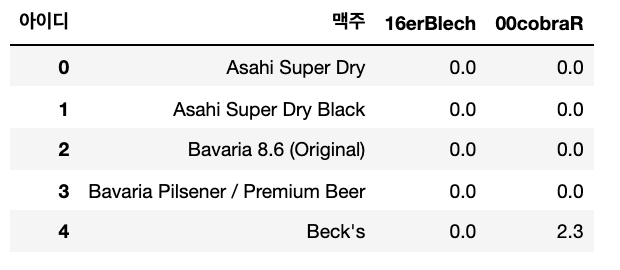
맥주 추천 - 나와 비슷한 취향을 가진 사용자가 별점을 높게 준 맥주들 추천
def recommend_beer_by_user(user):
# 자기 자신 제외 유사도 높은 사용자 리스트 (3명)
users=[]
users = get_similar_users(user, 4).index[1:4]
rcmmd_beer = []
for i in users:
print('user {}'.format(i))
# 이미 별점을 매긴(마셔본) 맥주 제외
# 유사도가 높은 사용자가 높게 별점을 준 맥주 리스트 받아옴
beer_list = list(del_rated_beer(tmp, user, i).sort_values(i, ascending=False)['맥주'][:5])
print(beer_list)
rcmmd_beer.append(beer_list)
return rcmmd_beer# 16erBlech
recommend_beer_by_user(username)
사용자가 마셔본 맥주가 없다면?
사용자가 마셔본 맥주가 없어 과거 정보를 바탕으로 유사도를 구할 수 없다면 사용자가 중요하게 생각하는 항목을 기준으로 평점을 다시 계산하여 상위 n개의 맥주 추천
- Aroma(향)
- Flavor(풍미)
- Mouthfeel(목넘김)
항목별 가중치 부과

(이전 포스팅에서 맥주 이름을 유니크값으로 만들어 항목별 평균값을 계산한 데이터프레임 이어서 이용)
순위별로 가중치 부과
# 사용자가 중요시 여기는 요인 순위 가정
first = 'Aroma'
second = 'Flavor'
third = 'Mouthfeel'
old_cols = [first, second, third]
# 가중치를 부과하여 새로 계산한 평점을 넣을 컬럼
new_cols = []
new_cols.append(first + '_new')
new_cols.append(second + '_new')
new_cols.append(third + '_new')
# 가중치
weights = [1, 0.5, 0.2]
# 가중치 부과한 평점 계산
for i in range(0, 3):
df[new_cols[i]] = df[old_cols[i]].apply(lambda x: x * weights[i])
총점(Overall) 계산
df.reset_index(inplace=True)
del df['index']
lenght = len(df)
overall_list = [] # 총점
for i in range(0, lenght):
overall = (format(df.loc[i, 'Aroma_new'] + df.loc[i, 'Flavor_new'] + df.loc[i, 'Mouthfeel_new']))
overall_list.append(overall)
df.insert(0, 'overall_new', overall_list)
상위 n개의 맥주 추천
def get_top_n_beer(df, n):
return df.sort_values(by='overall_new')['맥주'][:n]get_top_n_beer(df, 3)
728x90
'PYTHON > K-DIGITAL' 카테고리의 다른 글
| [K-DIGITAL] 파이널프로젝트. BEERCRAFT 맥주 추천 서비스(4) openCV YOLO 이용한 이미지 분석 (0) | 2021.08.11 |
|---|---|
| [K-DIGITAL] 파이널프로젝트. BEERCRAFT 맥주 추천 서비스(1) 데이터 수집부터 클러스터링까지 (0) | 2021.08.09 |
| [K-DIGITAL] Django 실습과 pythonanywhere 배포(2) 서비스 배포 (0) | 2021.08.03 |
| [K-DIGITAL] Django 실습과 pythonanywhere 배포(1) 웹 프로젝트 (0) | 2021.08.02 |
| [K-DIGITAL] 이미지 데이터 처리를 위한 CNN (0) | 2021.08.01 |
댓글 영역