고정 헤더 영역
상세 컨텐츠
본문
728x90
멋쟁이사자처럼 X K-DIGITAL Training - 06.09
필요한 라이브러리 준비
import numpy as np
import pandas as pdnumpy 벡터, 행렬 등 수치 연산을 수행하는 선형대수 라이브러리
pandas 데이터 처리 및 분석 라이브러리로 행과 열로 이루어진 데이터 객체(DataFrame)를 만들어 다룰 수 있음
데이터 읽어오기
1, 서울특별시 범죄 발생현황 통계자료
공공데이터 포털 참고 https://www.data.go.kr/data/15046348/fileData.do

엑셀 파일 읽기
- read_excel('파일명', encoding='utf-8')
df = pd.read_excel('서울특별시 범죄 발생현황 통계자료.xlsx', encoding='utf-8') # euc-kr / cp949데이터 확인
- head(n) 상위 n개(default 5개) 행 출력
- tail(n) 하위 n개(default 5개) 행 출력
df.head(n)
df.tail(n)
2. 서울시 인구 데이터

csv 파일 읽어오기
- read_csv('파일명', encoding, index_col) index_col 옵션으로 인덱스 열 선택하여 파일 open
popul_df = pd.read_csv('서울시 인구수.csv', encoding = 'UTF-8', index_col = '구별')
>> pandas.core.frame.DataFrame(데이터프레임) 타입 반환
데이터 전처리
관서명 구별로 정리하기
- 각 관서명(key)이 속한 구 이름(value)을 dict형태로 미리 정리
- 람다 함수를 이용하여 해당 관서명에 대응하는 구 이름을 새로운 열로 추가 (혹은 웹스크랩핑 이용 가능)
police_to_gu = {'서대문서': '서대문구', '수서서': '강남구', '강서서': '강서구', '서초서': '서초구',
'서부서': '은평구', '중부서': '중구', '종로서': '종로구', '남대문서': '중구',
'혜화서': '종로구', '용산서': '용산구', '성북서': '성북구', '동대문서': '동대문구',
'마포서': '마포구', '영등포서': '영등포구', '성동서': '성동구', '동작서': '동작구',
'광진서': '광진구', '강북서': '강북구', '금천서': '금천구', '중랑서': '중랑구',
'강남서': '강남구', '관악서': '관악구', '강동서': '강동구', '종암서': '성북구',
'구로서': '구로구', '양천서': '양천구', '송파서': '송파구', '노원서': '노원구',
'방배서': '서초구', '은평서': '은평구', '도봉서': '도봉구'}
df['구별'] = df['관서명'].apply(lambda x: police_to_gu.get(x, '구 없음'))
'구별' 열을 기준으로 범죄 발생, 검거 수 합계
- 피벗테이블 이용
pivot_table(데이터프레임, index = 인덱스 열, aggfunc = 채울 값)
gu_df = pd.pivot_table(df, index = '구별', aggfunc = np.sum)
컬럼(열) 정보 정리
- 검거율 계산
# 검거율 = 검거 / 발생 * 100
gu_df['강간검거율'] = gu_df['강간(검거)'] / gu_df['강간(발생)'] * 100
gu_df['강도검거율'] = gu_df['강도(검거)'] / gu_df['강도(발생)'] * 100
gu_df['살인검거율'] = gu_df['살인(검거)'] / gu_df['살인(발생)'] * 100
gu_df['절도검거율'] = gu_df['절도(검거)'] / gu_df['절도(발생)'] * 100
gu_df['폭력검거율'] = gu_df['폭력(검거)'] / gu_df['폭력(발생)'] * 100
gu_df['검거율'] = gu_df['소계(검거)'] / gu_df['소계(발생)'] * 100- 필요없는 열 삭제
del gu_df['강간(검거)']
del gu_df['강도(검거)']
del gu_df['살인(검거)']
del gu_df['절도(검거)']
del gu_df['폭력(검거)']
del gu_df['소계(발생)']
del gu_df['소계(검거)']- 열 이름 변경 ('강간(검거)' -> '강간')
gu_df.rename(columns = {'강간(발생)':'강간',
'강도(발생)':'강도',
'살인(발생)':'살인',
'절도(발생)':'절도',
'폭력(발생)':'폭력'
}, inplace = True) # 덮어쓰기 허용- 100 초과인 검거율 100으로 고정
(범죄 발생수는 올해만 해당되나 검거 수에는 발생년도와 상관없이 모든 범죄가 포함됨으로 검거율이 100을 넘기도 함)
# 검거율 정보만 출력 gu_df[[열 리스트]]
gu_df[['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']]
# bool값으로 출력
gu_df[['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']] > 100
# true인 값만 출력되어 100으로 덮어쓰어짐
gu_df[gu_df[['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']] > 100] = 100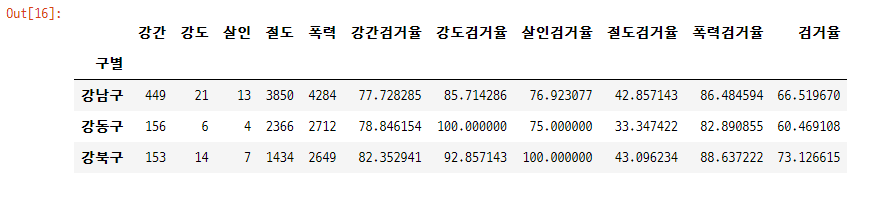
두 데이터프레임 합치기
1) 두 데이터프레임의 인덱스 열이 동일할 때
A.join(B)
gu_df = gu_df.join(popul_df)2) 두 데이터프레임의 인덱스 열이 다를 때 기준이 될 열을 지정하여
merge(A, B, left_on="A_index", right_on="B_index", how="join_type")
gu_df = pd.merge(gu_df, popul_df, left_on = '구별', right_on = '구별', how = 'inner')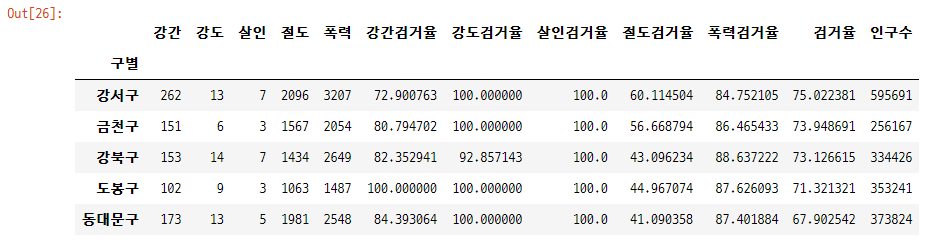
검거율 기준으로 내림차순 정렬
- sort_values(by='열 이름', 오름차순 여부(ascending), 덮어쓰기 여부(inplace))
# 오름차순
gu_df.sort_values(by = '검거율', ascending = True, inplace = True)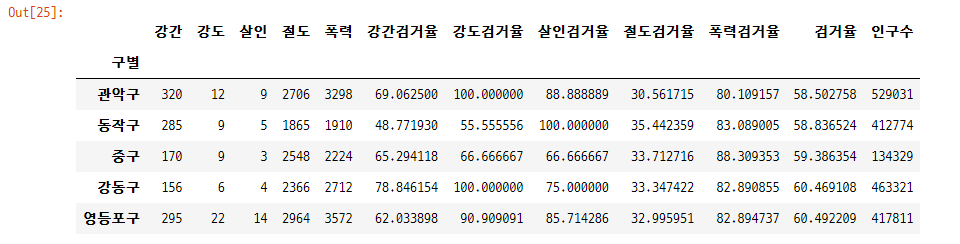
# 내림차순
gu_df.sort_values(by = '검거율', ascending = False, inplace = True)
각 범죄별 발생 건수 정규화
원하는 열만 사용하고자할 때 df[[열 이름 리스트]]
crime_list = ['강간', '강도', '살인', '절도', '폭력']
gu_df[crime_list]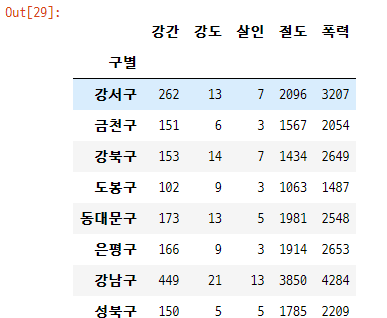
최대값 대비 비율 계산
- 각 5대 범죄별 발생 수치를 해당 범죄의 최대값으로 나눠줌
crime_list = ['강간', '강도', '살인', '절도', '폭력']
weight_col = gu_df[crime_list].max() # 각 범죄별 최대값
crime_count_norm = gu_df[crime_list] / weight_col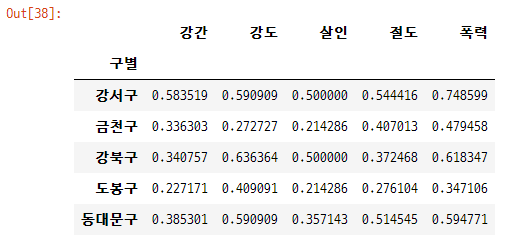
인구 수 대비 비율 계산
- 구 별(행)로 구별 범죄 수(최대값 대비 비율값) / 구별 인구 수 * 1000(인구 수 단위)
crime_ratio = crime_count_norm.div(gu_df['인구수'], axis = 0) * 100000
728x90
'PYTHON > K-DIGITAL' 카테고리의 다른 글
| [K-DIGITAL] 파이썬을 활용한 기초 통계분석(2) 상관관계 (0) | 2021.06.22 |
|---|---|
| [K-DIGITAL] 파이썬을 활용한 기초 통계분석(1) 빈도 분석과 이상치 (0) | 2021.06.21 |
| [K-DIGITAL] 세미프로젝트1. 서울시 자전거사고 분석(2) 원인예측 (0) | 2021.06.19 |
| [K-DIGITAL] 세미프로젝트1. 서울시 자전거사고 분석(1) 문제분석 (0) | 2021.06.18 |
| [K-DIGITAL] 파이썬 통계자료 분석 및 시각화(2) 데이터 시각화 (0) | 2021.06.16 |
댓글 영역