고정 헤더 영역
상세 컨텐츠
본문
728x90
멋쟁이사자처럼 X K-DIGITAL Training - 06.18
[github] likelion-kdigital/semi-project-1 https://github.com/ijo0r98/likelion-kdigital/tree/main/semi-project-1
ijo0r98/likelion-kdigital
멋쟁이사자처럼 & K-Digital Training✏. Contribute to ijo0r98/likelion-kdigital development by creating an account on GitHub.
github.com
[이전] 세미프로젝트1. 서울시 자전거사고 분석(1) 문제분석
2021.06.18 - [python/K-Digital] - [K-DIGITAL] 세미프로젝트1. 서울시 자전거사고 분석(1) 문제분석
[K-DIGITAL] 세미프로젝트1. 서울시 자전거사고 분석(1) 문제분석
멋쟁이사자처럼 X K-DIGITAL Training - 06.17 [github] likelion-kdigital/semi-project-1 https://github.com/ijo0r98/likelion-kdigital/tree/main/semi-project-1 ijo0r98/likelion-kdigital 멋쟁이사자처럼..
juran-devblog.tistory.com
사고 발생건수가 가장 많은 영등포구와 송파구의 공통된 특징 분석
0. 구별 공공자전거 이용정보
http://data.seoul.go.kr/dataList/OA-15182/F/1/datasetView.do
서울특별시 공공자전거 대여이력 정보
서울특별시 공공자전거 대여이력 정보입니다. 자전거 이동경로에 대한 데이터 분석이 가능하도록
년도별, 대여소별, 자전거별 대여이력 원천 데이터를 제공합니다.
data.seoul.go.kr
데이터 전처리
bicycle_using_df = pd.read_excel('data/공공자전거 대여소별 이용정보_202006.csv', encoding='utf-8')
bicycle_using_df = bicycle_using_df.drop(['대여소 명', '대여 일자 / 월'], axis =1)
bicycle_using_df.rename(columns = {'대여소 그룹':'지역'}, inplace = True)
bicycle_using_df = bicycle_using_df.groupby(bicycle_using_df['지역']).sum()대여 건수 기준 오름차순 정렬
bicycle_using_df.sort_values(by='대여 건수', ascending=False).head()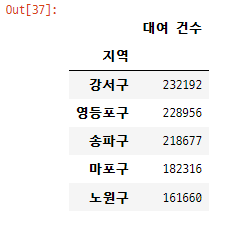
(구별 인구를 고려하지 않았을 때) 강서구, 영등포구, 송파구의 공공자전거 이용률이 가장 높음
1. 사고다발지역의 특징
1) 서울시 자전거도로 현황 데이터
서울시 자전거도로
서울시 자전거 도로
data-esrikrmkt.opendata.arcgis.com
geo_path = 'data/서울시자전거도로.geojson'
df_bic_road_geo = json.load(open(geo_path, encoding = 'utf-8'))지도 시각화
map_bic_road = folium.Map(location=[37.5502, 126.982], zoom_start=11)
map_bic_road.choropleth(geo_data = df_bic_road_geo,
line_color = 'black',
line_weight=1.5,
line_opacity=0.5,
key_on = 'feature.id') 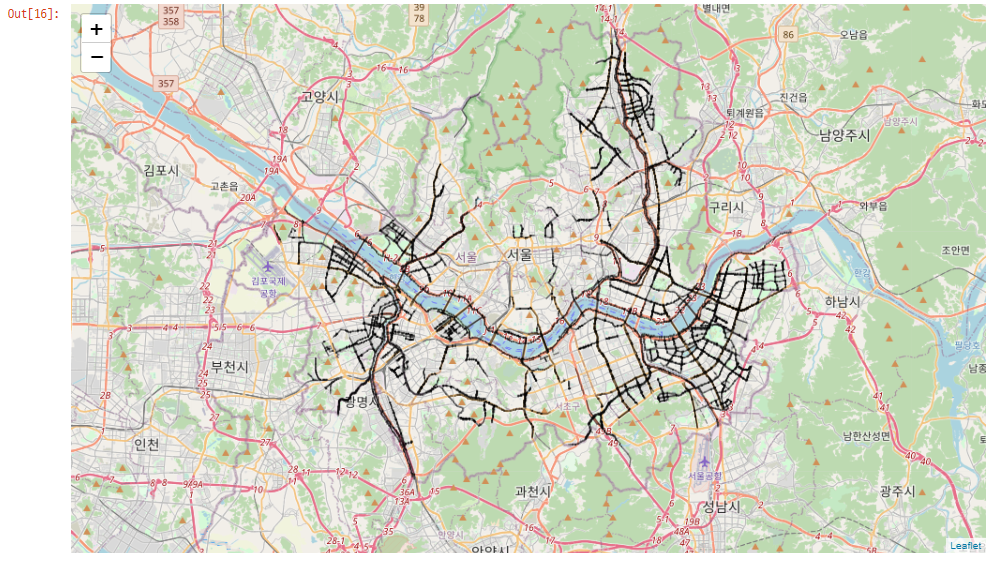
2) 자전거사고 다발지역 Open API
https://www.data.go.kr/data/15056681/openapi.do
도로교통공단_자전거사고다발지역정보서비스
교통사고정보를 위치데이터 기반 제공 교통사고 항목 별 정보제공
www.data.go.kr
서울시내 전체 구,군 코드
guGun_list2 = {
'강남구': '680', '강동구': '740', '강북구': '305', '강서구': '500', '관악구': '620',
'광진구': '215', '구로구': '530', '금천구': '545', '노원구': '350', '도봉구': '320',
'동대문구': '230', '동작구': '590', '마포구': '440', '서대문구': '410', '서초구': '650',
'성동구': '200', '성북구': '290', '송파구': '710', '양천구': '470', '영등포구': '560',
'용산구': '170', '은평구': '380', '종로구': '110', '중구': '140', '중랑구': '260'
}query param
service_key = '{api_key}'
base_url = 'http://apis.data.go.kr/B552061/frequentzoneBicycle/getRestFrequentzoneBicycle'
searchYearCd = '2015'
siDo = '11'
type = 'xml'
numOfRows = '100'
pageNo = '1'API 호출
gu_nm = [] # 지역구명
spot_nm = [] # 장소명
lat = [] # 위도
lnd = [] # 경도
for key, guGun in guGun_list2.items():
request_url = base_url + '?' + "serviceKey=" + service_key + '&searchYearCd=' + searchYearCd + '&siDo=' + siDo + '&guGun=' + guGun+ '&type=' + type + '&numOfRows=' + numOfRows + '&pageNo=' + pageNo
try:
response = requests.get(request_url)
soup = BeautifulSoup(response.text, 'lxml-xml')
for value in soup.find('body').find_all('lo_crd'):
gu_nm.append(key)
lnd.append(value.get_text())
for value in soup.find('body').find_all('la_crd'):
lat.append(value.get_text())
for item in soup.find('body').find_all('item'):
spot_nm.append(item.find('spot_nm').get_text())
except:
pass데이터프레임으로 전환
df_acc_prone = pd.DataFrame({'구별': gu_nm, '장소명': spot_nm, 'lat': lat, 'lnd': lnd})
서울시 자전거도로 지도 위 사고다발지역 시각화
for n in df_acc_prone.index:
folium.Circle(location=[float(df_acc_prone.lat[n]), float(df_acc_prone.lnd[n])], popup=df_acc_prone['장소명'][n], color='red').add_to(map_bic_road)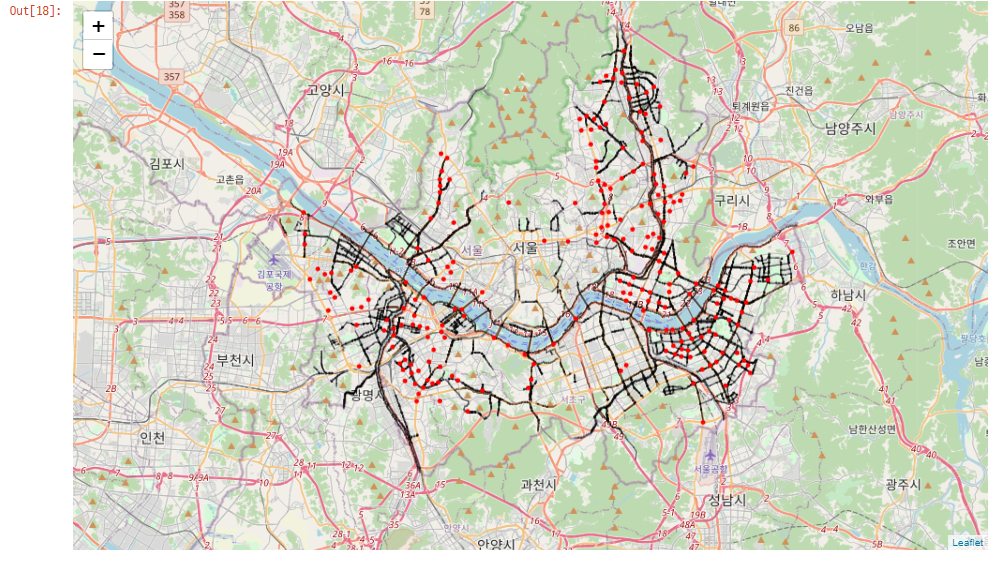
대부분의 경우 자전거 도로 위에서 사고 발생
2. 자전거도로 수와 비율
1) 자전거도로 수
http://data.seoul.go.kr/dataList/276/S/2/datasetView.do
서울시 자전거도로 현황 통계
○ 통계개요
* 통계명 : 자전거도로 현황
* 통계종류 : 서울시 자전거도로 현황을 제공하는 일반ㆍ보고통계
* 작성목적 : 자전거 이용시설의 정비 및 자전거 이용자의 안전과 편의를
data.seoul.go.kr
데이터 전처리
df_bic_road_csv = pd.read_excel('data/서울시_자전거도로현황.xlsx', encoding='utf-8')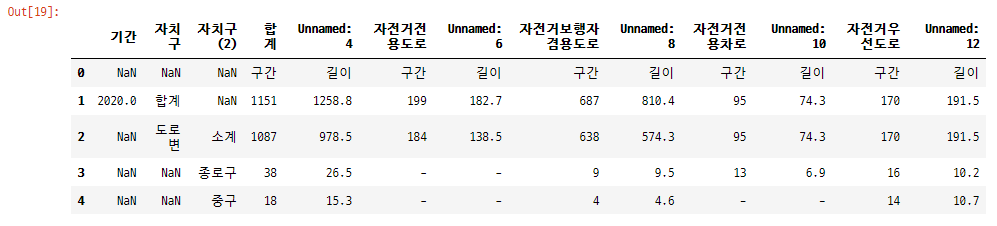
- 필요없는 행과 열 삭제
del df_bic_road_csv['기간']
del df_bic_road_csv['자치구']
df_bic_road_csv.dropna(axis=0, inplace=True)
df_bic_road_csv.drop([2, 28, 29, 30, 31], inplace=True)- 문자열 데이터(빈 값) 0으로 치환
df_bic_road_csv.replace('-', 0, inplace=True)- 컬럼명 변경
# 기존 컬럼명 리스트
column_list = list(df_bic_road_csv.columns)
# 새 컬럼명 리스트
new_column_list = []
for index, value in enumerate(column_list):
if value.startswith('Unnamed'):
new_column_list.insert(index, column_list[index - 1] + ' 길이')
new_column_list.insert(index - 1, column_list[index - 1] + ' 구간')
elif value == '자치구(2)':
new_column_list.insert(index, '구별')
# 컬럼명 변경에 쓰일 dict
column_dict = dict(zip(column_list,new_column_list))
# 컬럼명 변경
df_bic_road_csv.rename(columns=column_dict, inplace=True)- 인덱스 변경
df_bic_road_csv.set_index('구별', inplace=True)
지도 시각화
geo_path = 'data/skorea_municipalities_geo_simple.json'
geo_str = json.load(open(geo_path, 'r', encoding = 'utf-8'))
map_road_cnt = folium.Map(location=[37.5502, 126.982], zoom_start=11, tiles='Stamen Toner')
map_road_cnt.choropleth(geo_data = geo_str,
data = df_bic_road_csv['합계 구간'],
columns = [df_bic_road_csv.index, df_bic_road_csv['합계 구간']],
fill_color = 'BuGn',
key_on = 'feature.id')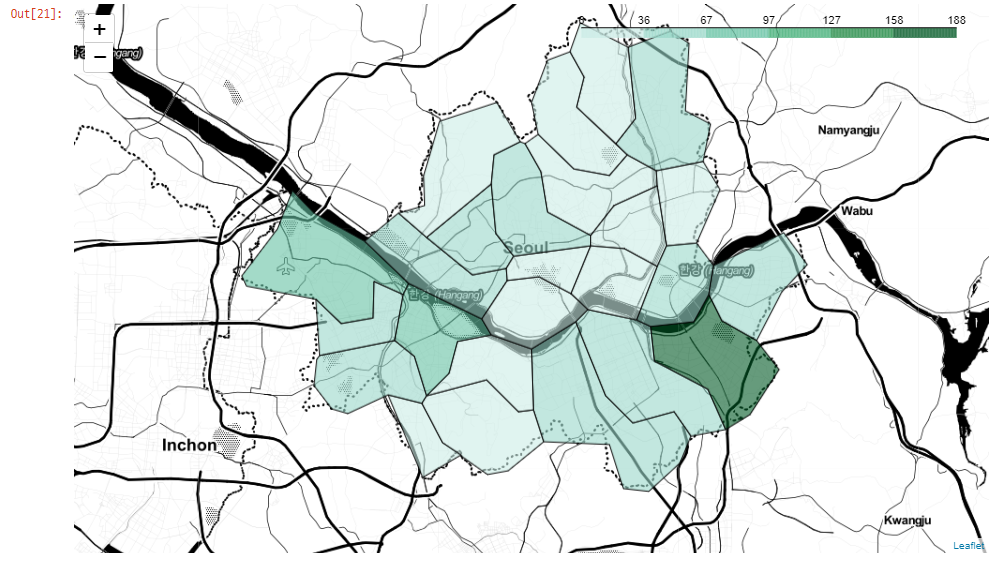
합계 기준 오름차순 정렬
df_bic_road_csv.sort_values(by='합계 구간', ascending=False).head(3)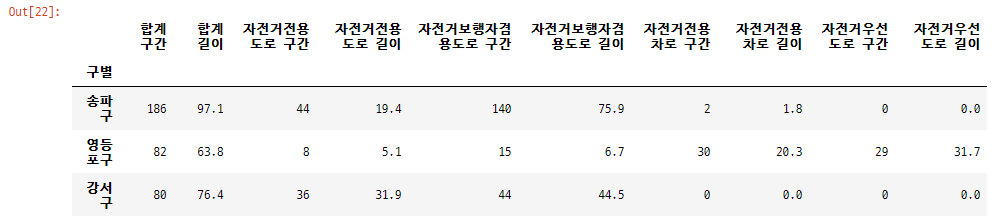
송파구와 영등포구, 강서구에 자전거도로가 가장 많음을 알 수 있음
2) [인구 수 대비] 자전거도로 수
인구 수 데이터

자전거도로 현황 데이터

두 데이터 JOIN
df_bic_road_csv = df_bic_road_csv.join(popul_df)
인구 수 대비 정규화
# 각 열의 최대값으로 나눔
weight_col = df_bic_road_csv[target_col].max()
bicycle_load_norm = df_bic_road_csv[target_col] / weight_col
# 인구수 대비 비율 계산
bicycle_load_ratio = bicycle_load_norm.div(df_bic_road_csv['인구수'] , axis=0 ) * 100000
bicycle_load_ratio.sort_values(by='합계 구간', ascending=False).head()
히트맵으로 시각화
plt.figure(figsize = (10,10))
sns.heatmap(bicycle_load_ratio.sort_values(by='합계 구간', ascending=False), annot=True, fmt='f', linewidths=.5, cmap='Greens')
plt.title('[인구 수 대비] 서울시 자전거 도로 현황')
plt.show()
지도 시각화
geo_path = 'data/skorea_municipalities_geo_simple.json'
geo_str = json.load(open(geo_path, 'r', encoding = 'utf-8'))
map_road_cnt_popul = folium.Map(location=[37.5502, 126.982], zoom_start=11, tiles='Stamen Toner')
map_road_cnt_popul.choropleth(geo_data = geo_str,
data = df_bic_road_csv['합계 구간'],
columns = [df_bic_road_csv.index, df_bic_road_csv['합계 구간']],
fill_color = 'BuGn',
key_on = 'feature.id')
합계 기준 오름차순으로 정렬
bicycle_load_ratio.sort_values(by='합계 구간', ascending=False).head(3)
인구 수에 대비했을 때 송파구와 종로구, 영등포구에 자전거도로가 가장 많음을 알 수 있음
3. 자전거도로의 종류
송파구와 영등포구의 자전거도로 현황 데이터
road_list = ['자전거전용도로 구간', '자전거보행자겸용도로 구간', '자전거전용차로 구간', '자전거우선도로 구간']
df_bic_road_csv.loc[['종로구', '영등포구'], road_list]
종로구의 자전거도로 현황 파이차트
df_bic_road_csv.loc['종로구', road_list].plot(kind='pie', autopct='%.1f%%',figsize=(20, 15), fontsize=20, colormap='Set3')
영등포구의 자전거도로 현황 파이차트
df_bic_road_csv.loc['영등포구', road_list].plot(kind='pie', autopct='%.1f%%',figsize=(20, 15), fontsize=20, colormap='Set3')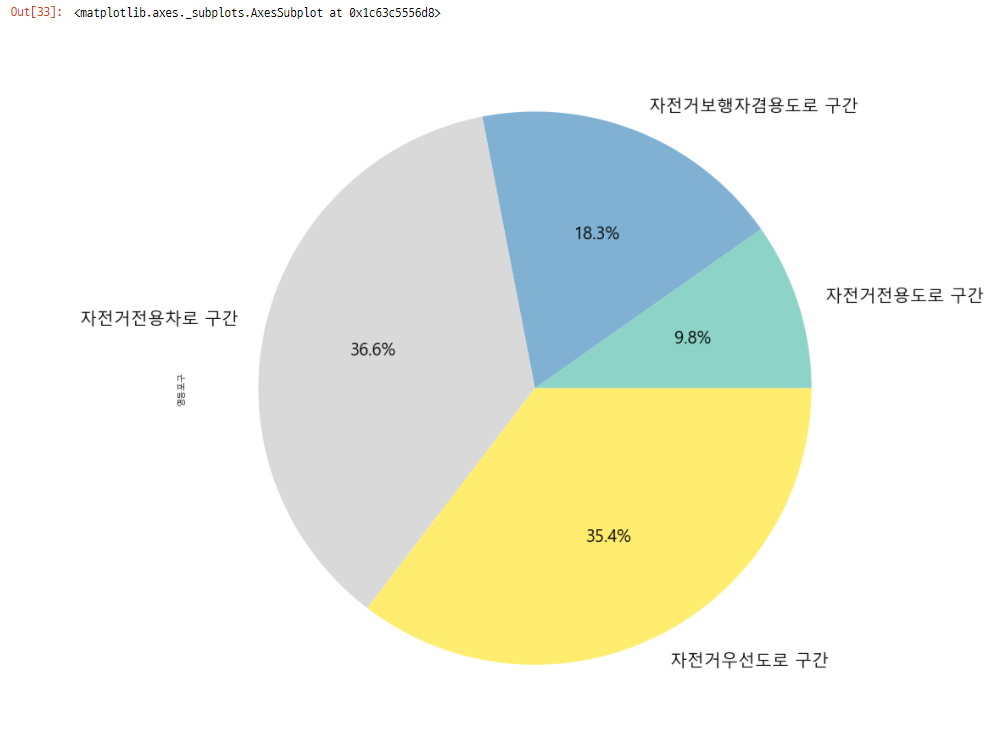
웹 스크랩핑으로 알아본 자전거도로의 종류
https://www.koroad.or.kr/kp_web/knTwoWheel3-03.do
도로교통공단
www.koroad.or.kr
웹 스크랩핑
url = 'https://www.koroad.or.kr/kp_web/knTwoWheel3-03.do'
response = requests.get(url).content
source = BeautifulSoup(response, 'html.parser')
# 도로 종류
road_nm = []
for item in source.find_all('h4')[-5:]:
road_nm.append(item.get_text())
# 도로 설명
road_info = []
for index, item in enumerate(source.find_all('ul', {'class': 'list2'})):
road_info.append((item.find('li').get_text()).strip())데이터프레임으로 전환
# 데이터프레임으로 전환
df_road_info = pd.DataFrame({'도로 종류': road_nm, '설명': road_info})
더보기
셀 최대 넓이 지정
pd.set_option('display.max.colwidth', 100)
두 지역 모두 자동차와 함께 통행하는 자전거 우선도로, 전용차로의 비율이 가장 높음
자전거만 다닐 수 있는 비교적 안전한 자전거 전용도로의 비율이 적음을 알 수 있음
자전거 교통사고 발생이 높은 곳의 특징
- 자전거 도로가 많다.
- 자전거 이용률(공공자전거 기준)이 높다.
- 자전거 우선도로와 전용차로의 비율이 높고 자전거 전용도로의 비율이 적다.
[원인 예측]
자전거 사고 발생 수는 자전거 도로 수, 자전거 이용률과 상관관계가 있을 것이다.
자전거 우선도로와 전용차로가 자전거 사고 발생에 주는 영향이 가장 클 것이다.
→ 자전거 도로 수와 이용률에 비해 자전거 전용도로의 비율이 적어 안전한 자전거 도로상황이 아니기 때문이라고 예상
728x90
'PYTHON > K-DIGITAL' 카테고리의 다른 글
| [K-DIGITAL] 파이썬을 활용한 기초 통계분석(2) 상관관계 (0) | 2021.06.22 |
|---|---|
| [K-DIGITAL] 파이썬을 활용한 기초 통계분석(1) 빈도 분석과 이상치 (0) | 2021.06.21 |
| [K-DIGITAL] 세미프로젝트1. 서울시 자전거사고 분석(1) 문제분석 (0) | 2021.06.18 |
| [K-DIGITAL] 파이썬 통계자료 분석 및 시각화(2) 데이터 시각화 (0) | 2021.06.16 |
| [K-DIGITAL] 파이썬 통계자료 분석 및 시각화(1) 데이터 전처리 (0) | 2021.06.15 |
댓글 영역