고정 헤더 영역
상세 컨텐츠
본문
728x90
멋쟁이사자처럼 X K-DIGITAL Training - 06.11
웹 스크랩핑 vs 웹 크롤링
웹 스크랩핑 (scraping)
웹 사이트 상에서 원하는 정보를 추출하는 기술
특정 웹 사이트 또는 페이지에서 특정 정보 검색
웹 크롤링 (crawling)
웹 크롤러(자동화 봇)가 일정 규칙으로 웹페이지 브라우징(탐색) 하는 것
웹 크롤러(crawler)는 사이트나 네트워크가 제공할 수 있는 것을 끝없이 탐색하면서 스스로 웹 페이지를 탐색할 수 있는 프로그램의 능력을 의미
검색 엔진에서 url의 콘첸츠를 추출하고 이 페이지에서 다시 다른 링크를 확인하고 링크의 url을 가져오는데 주로 사용
검색 결과에서 뉴스 기사 스크랩하기
라이브러리
import requests
from bs4 import BeautifulSoup
import pandas as pd
from datetime import datetime
import time
import rerequets 파이썬 HTTP 라이브러리
bs4.BeautifulSoup HTML과 XML 파싱하기 위한 파이썬 패키지
pandas 데이터프레임 생성하여 행과 열의 데이터를 다룰 수 있게 해줌
datetime 날짜를 다루기 위한 모듈
time 시간을 다루기 위한 모듈
re 정규식
검색 결과에서 뉴스 제목 추려내기
원하는 키워드로 네이버 뉴스 탭에 http get요청
query = '배우 박정민'
url = "https://search.naver.com/search.naver?where=news&query=" + query
web = requests.get(url).content # get 요청
source = BeautifulSoup(web, 'html.parser')>> 'https://search.naver.com/search.naver?where=news&query=배우 박정민'

뉴스 제목과 url 읽어오기
- 뉴스 제목 리스트
subjects = source.find_all('a', {'class': 'news_tit'})
subjects_list = []
for subject in subjects:
subjects_list.append(subject.get_text())
subjects_list
- 뉴스 url 리스트
urls_list = []
for url in subjects:
urls_list.append(url.attrs['href']) # url['href']
urls_list
단일 기사 본문 스크랩핑
* 언론사 뉴시스 기사 기준
url = 'https://newsis.com/view/?id=NISX20210602_0001462205&cID=10601&pID=10600'
news_content = requests.get(url).content
source = BeautifulSoup(news_content, 'html.parser')

* 접속이 차단당할 때 헤더 설정
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
news_content = requests.get(urls_list[7], headers=headers).content
source = BeautifulSoup(news_content, 'html.parser')
뉴스 제목
source.find('h1').get_text()>> "'유 퀴즈' 배우 박정민→윤여정 동생 윤여순 출연"
뉴스 발행 시간
date_source = source.find('div', {'class': 'date'}).get_text()>> '등록 2021-06-02 13:51:26'
- date 라이브러리 이용하여 날짜 유형 바꾸기
year = date_source[3:7]
month = date_source[8:10]
day = date_source[11:13]
hh = date_source[14:16]
mm = date_source[17:19]
ss = date_source[20:22]
print('{}년 {}월 {}일 {}시 {}분 {}초 발행'.format(year, month, day, hh, mm, ss))>> 2021년 06월 02일 13시 51분 26초 발행
press_date = year + month + day + hh + mm + ss
press_date_ts = pd.Timestamp(press_date)>> Timestamp('2021-06-02 13:51:26')
기사 본문
article = source.find('div', {'id': 'textBody'}).get_text()
print(article) # \n -> 줄바꿈으로 출력
- 무의미한 부분 삭제
news_content = article.replace('[서울=뉴시스]', '')
news_content = news_content.replace('◎공감언론 뉴시스 akang@newsis.com', '')
news_content = news_content.replace('\n\r\n', ' ')
news_content = news_content.replace('\n\n\n\t', ' ')
- 정규식 이용하여 무의미한 부분 확인
pattern = re.compile(r'@') # 처음 등장하는 @ 위치
email_address = pattern.search(news_content)
email_address>> <re.Match object; span=(72, 73), match='@'>
- @ 시작 위치
email_address.start()>> 72
- @ ~ 삭제해야할 부분
news_content[email_address.start():email_address.start() + 21]>> '@newsis.com 강진아 기자 = '
- '처음 ~ @newsis.com 000 기자 = ' 삭제
# @ ~ newsis.com 000 기자 = -> 21글자 동일
mail_start = email_address.start()
news_content = news_content[mail_start + 21:]
- \' 삭제
pattern = re.compile(r'\'')
news_content = pattern.sub('', news_content)
발행언론사
article[-26:-1]>> '공감언론 뉴시스 akang@newsis.com'
source.find('div', {'class': 'copy'}).get_text()>> 'Copyright © NEWSIS.COM, 무단 전재 및 재배포 금지'
여러 뉴스 기사 모으기
urls_list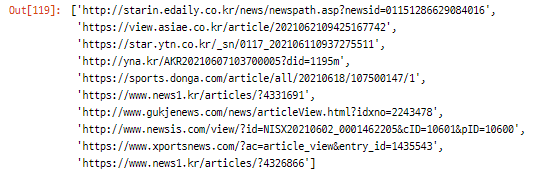
* 언론사마다 뉴스 본문이 들어있는 div가 다르기 때문에 뉴시스 언론사의 기사만 스크랩할 예정
titles = [] # 기사 제목
dates = [] # 발행 일자와 시간
articles = [] # 내용
press_companies = [] # 발행사
urls = [] # urlfor url in urls_list:
if url.startswith('http://www.newsis.com'):
try:
content = requests.get(url).content
source = BeautifulSoup(content, 'html.parser')
# 기사제목
title = source.find('h1').get_text()
# 기사날짜
date = source.find('div', {'class': 'date'}).get_text()[3:]
# 기사본문
article = source.find('div', {'id': 'textBody'}).get_text()
news_content = article.replace('[서울=뉴시스]', '')
news_content = news_content.replace('◎공감언론 뉴시스 akang@newsis.com', '')
news_content = news_content.replace('\n\r\n', ' ')
news_content = news_content.replace('\n\n\n\t', ' ')
pattern = re.compile(r'@') # 처음 등장하는 @ 위치
email_address = pattern.search(news_content)
mail_start = email_address.start()
news_content = news_content[mail_start + 21:]
# 언론사
press_company = article[-26:-1]
titles.append(title)
dates.append(date)
articles.append(news_content)
press_companies.append(press_company)
urls.append(url)
print('Title: {}'.format(url))
except:
print('*** error occurred at {} ***'.format(url))
else:
print('** (뉴시스x) Title: {}'.format(url))
(생각보다 뉴시스 언론사 기사가 몇개 없어서 당황🤔)
데이터프레임 생성
df_article = pd.DataFrame({'Title': titles, 'Date': dates, 'Article': articles, 'URL': url, 'Press Company': press_companies})
- 현재 날짜와 시간
datetime.now()>> datetime.datetime(2021, 6, 23, 0, 17, 11, 785551)
엑셀 파일로 저장
df_article.to_excel('result_{}.xlsx'.format(datetime.now().strftime('%y%m%d_%H%M')), index=False, encoding='utf-8')
메서드화
해당 url의 기사 제목, 날짜, 본문, 언론사, url 스크랩
def scraping_news(url, titles, dates, articles, press_companies, urls):
if url.startswith('http://www.newsis.com'):
try:
content = requests.get(url).content
source = BeautifulSoup(content, 'html.parser')
# 기사제목
title = source.find('h1').get_text()
# 기사날짜
date = source.find('div', {'class': 'date'}).get_text()[3:]
# 기사본문
article = source.find('div', {'id': 'textBody'}).get_text()
news_content = article.replace('[서울=뉴시스]', '')
news_content = news_content.replace('◎공감언론 뉴시스 akang@newsis.com', '')
news_content = news_content.replace('\n\r\n', ' ')
news_content = news_content.replace('\n\n\n\t', ' ')
pattern = re.compile(r'@') # 처음 등장하는 @ 위치
email_address = pattern.search(news_content)
mail_start = email_address.start()
news_content = news_content[mail_start + 21:]
# 언론사
press_company = article[-26:-1]
titles.append(title)
dates.append(date)
articles.append(news_content)
press_companies.append(press_company)
urls.append(url)
print('Title: {}'.format(url))
except:
print('*** error occurred at {} ***'.format(url))
else:
print('*** (뉴시스x) Title: {} ***'.format(url))데이터프레임으로 생성
def make_dateframe(titles, dates, articles, urls, presscompanies):
return pd.DataFrame({'Title':titles,
'Date':dates,
'Article':articles,
'URL':urls,
'PressCompany':presscompanies})
여러 페이지에 걸쳐 크롤링하기

한 페이지당 10개의 기사글 존재
# 처음 시작 (~10)
query = '배우 박정민'
# start =
url = "https://search.naver.com/search.naver?where=news&query=" + query
# 2페이지 시작 (11~20)
query = '배우 박정민'
start = 11
url = "https://search.naver.com/search.naver?where=news&query=" + query + '&start=' + str(start)
# 3페이지 시작 (21~30)
query = '배우 박정민'
start = 21
url = "https://search.naver.com/search.naver?where=news&query=" + query + '&start=' + str(start)크롤링할 최대 페이지가 정해졌을 때 각 페이지 start
max_page = 5
starts = []
for i in range(1, max_page * 10 + 1, 10):
print(i)>> 1, 11, 21, 31, 41
원하는 페이지 수 지정하여 기사들의 본문 내용 스크랩핑 하기
query = (input('검색할 단어를 입력하세요: '))
max_page = (input('검색할 총 페이지수를 입력하세요: '))
current = 1
last = int(max_page) * 10 + 1
base_url = 'https://search.naver.com/search.naver?where=news&query='
titles = []
dates = []
articles = []
press_companies = []
urls = []
while current <= last:
print('\n{}번째 기사글부터 크롤링을 시작합니다.'.format(current))
# 페이지 이동
url = base_url + query + '&start=' + str(current)
web = requests.get(url).content
source = BeautifulSoup(web, 'html.parser')
# 각 페이지 url에서 기사 url 스크랩
urls_list = []
for url in source.find_all('a', {'class': 'news_tit'}):
urls_list.append(url['href'])
# 각 url에 접속하여 기사 본문 스크랩
for url in urls_list:
scraping_news(url, titles, dates, articles, press_companies, urls)
# 접속 차단 방지를 위해 몇초간 sleep
time.sleep(5)
current += 10
# 데이터프레임 생성
df_article = pd.DataFrame({'Title':titles, 'Date':dates, 'Article':articles, 'URL':urls, 'Press Company': press_companies})
- titles

- dates

데이터프레임 엑셀파일로 저장
df_article.to_excel('resultAll_{}.xlsx'.format(datetime.now().strftime('%y%m%d_%H%M')), index=False, encoding='utf-8')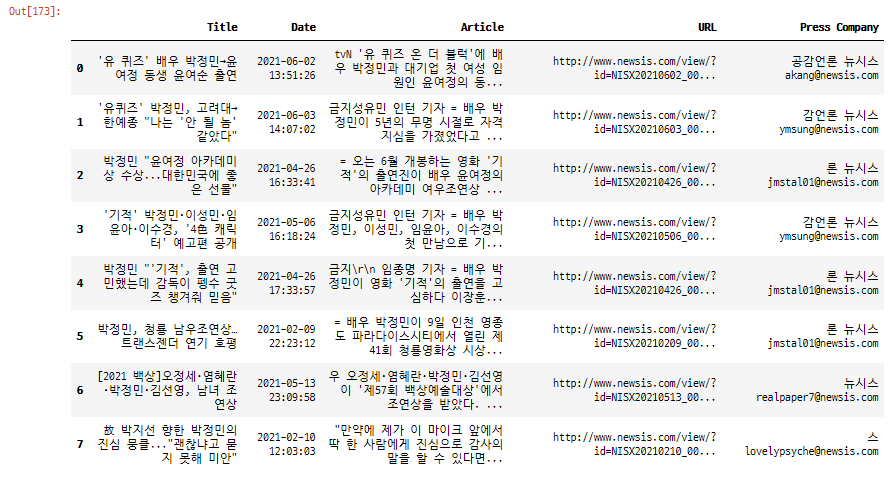
조건에 따라 크롤링하기
날짜
query = (input('검색할 단어를 입력하세요: '))
start_date = '2021-06-22'.replace('.','')
end_date='2021-06-20'.replace('.','')
current = 1
last = int(max_page) * 10 + 1
base_url = 'https://search.naver.com/search.naver?where=news&query='
titles = []
dates = []
articles = []
press_companies = []
urls = []
# while current <= last:
print('크롤링을 시작합니다.')
url = base_url + query + '&nso=so%3Ar%2Cp%3Afrom' + start_date + 'to' + end_date + '%2Ca%3A&start=1'
web = requests.get(url).content
source = BeautifulSoup(web, 'html.parser')
urls_list = []
for url in source.find_all('a', {'class': 'news_tit'}):
urls_list.append(url['href'])
for url in urls_list:
scraping_news(url, titles, dates, articles, press_companies, urls)
df_10cm = make_dateframe(titles, dates, articles, urls, press_companies)
정렬 순서
query = (input('검색할 단어를 입력하세요: '))
max_page = (input('검색할 총 페이지수를 입력하세요: '))
sort_type = (input('정렬 순서를 입력하세요(0:관련도순, 1:최신순, 2:오래된순: '))
current = 1
last = int(max_page) * 10 + 1
base_url = 'https://search.naver.com/search.naver?where=news&query='
titles = []
dates = []
articles = []
press_companies = []
urls = []
while current <= last:
print('\n{}번째 기사글부터 크롤링을 시작합니다.'.format(current))
url = base_url + query + "&sort=" + str(sort_type) + "&start=" + str(current)
web = requests.get(url).content
source = BeautifulSoup(web, 'html.parser')
urls_list = []
for item in source.find_all('a', {'class': 'news_tit'}):
urls_list.append(item['href'])
for url in urls_list:
scraping_news(url, titles, dates, articles, press_companies, urls)
time.sleep(5)
current += 10
df = make_dateframe(titles, dates, articles, urls, press_companies)728x90
'PYTHON > K-DIGITAL' 카테고리의 다른 글
| [K-DIGITAL] 파이썬 텍스트 데이터 분석 (0) | 2021.06.25 |
|---|---|
| [K-DIGITAL] 파이썬 웹 크롤링 - 뉴스 기사 스크랩(2) (0) | 2021.06.23 |
| [K-DIGITAL] 세미프로젝트1. 서울시 자전거사고 분석(4) 추가, 수정 (0) | 2021.06.22 |
| [K-DIGITAL] 세미프로젝트1. 서울시 자전거사고 분석(3) 상관관계 (0) | 2021.06.22 |
| [K-DIGITAL] 파이썬을 활용한 기초 통계분석(2) 상관관계 (0) | 2021.06.22 |
댓글 영역