고정 헤더 영역
상세 컨텐츠
본문
728x90
멋쟁이사자처럼 X K-DIGITAL Training - 06.21
[github] likelion-kdigital/semi-project-1 https://github.com/ijo0r98/likelion-kdigital/tree/main/semi-project-1
ijo0r98/likelion-kdigital
멋쟁이사자처럼 & K-Digital Training✏. Contribute to ijo0r98/likelion-kdigital development by creating an account on GitHub.
github.com
[이전]
세미프로젝트1. 서울시 자전거사고 분석(1) 문제분석
2021.06.18 - [python/K-Digital] - [K-DIGITAL] 세미프로젝트1. 서울시 자전거사고 분석(1) 문제분석
[K-DIGITAL] 세미프로젝트1. 서울시 자전거사고 분석(1) 문제분석
멋쟁이사자처럼 X K-DIGITAL Training - 06.17 [github] likelion-kdigital/semi-project-1 https://github.com/ijo0r98/likelion-kdigital/tree/main/semi-project-1 ijo0r98/likelion-kdigital 멋쟁이사자처럼..
juran-devblog.tistory.com
세미프로젝트1. 서울시 자전거사고 분석(2) 원인예측
2021.06.19 - [python/K-Digital] - [K-DIGITAL] 세미프로젝트1. 서울시 자전거사고 분석(2) 원인예측
[K-DIGITAL] 세미프로젝트1. 서울시 자전거사고 분석(2) 원인예측
멋쟁이사자처럼 X K-DIGITAL Training - 06.18 [github] likelion-kdigital/semi-project-1 https://github.com/ijo0r98/likelion-kdigital/tree/main/semi-project-1 ijo0r98/likelion-kdigital 멋쟁이사자처럼..
juran-devblog.tistory.com
[참고]
2021.06.22 - [python/K-Digital] - [K-DIGITAL] 파이썬을 활용한 기초 통계분석(2) 상관관계
[K-DIGITAL] 파이썬을 활용한 기초 통계분석(2) 상관관계
멋쟁이사자처럼 X K-DIGITAL Training - 06.16 [이전] 2021.06.21 - [python/K-Digital] - [K-DIGITAL] 파이썬을 활용한 기초 통계분석(1) 빈도 분석과 이상치 [K-DIGITAL] 파이썬을 활용한 기초 통계분석(1) 빈도..
juran-devblog.tistory.com
자전거 교통사고 발생 건수와 여러 요인사이 상관관계 분석
라이브러리 추가
from scipy import statsscipy.stats 각종 수치 해석 기능 제공
상관관계 분석
0. 개요
데이터 전처리
# 인구수 열 추가
df_bic_acc_corr = df_bic_road_csv[['합계 구간', '인구수']].join(bicycle_using_df)
# 사고 합계 열 추가
df_bic_acc_corr = df_bic_acc_corr.join(df_bic_acc['합계'])
# 이름 변경
df_bic_acc_corr.rename(columns={'합계': '사고 합계'}, inplace=True)
df_bic_acc_corr.rename(columns={'인구수': '인구 수'}, inplace=True)
df_bic_acc_corr.rename(columns={'합계 구간': '도로 수'}, inplace=True)
df_bic_acc_corr.rename(columns={'사고 합계': '사고 수'}, inplace=True)
상관관계
df_bic_acc_corr.corr()
* p-value 기준 0.05
1. 인구 수
result = stats.pearsonr(df_bic_acc_corr['사고 수'], df_bic_acc_corr['인구 수'])
print('피어슨 상관계수: {} / p-value: {}'.format(result[0], result[1]))>> 피어슨 상관계수: 0.5879502137132394 / p-value: 0.0019955938257670727
p-value가 0.05 미만임으로 구별 자전거 교통사고 수와 인구가 통계적으로 유의미한 상관관계(0.58)가 있다.
2. 자전거 이용(공공자전거 대여 건수 기준)
result = stats.pearsonr(df_bic_acc_corr['사고 수'], df_bic_acc_corr['대여 건수'])
print('피어슨 상관계수: {} / p-value: {}'.format(result[0], result[1]))>> 피어슨 상관계수: 0.7094286935730393 / p-value: 7.158608306045672e-05
p-value가 0.05 미만임으로 구별 자전거 교통사고 수와 공공자전거 대여 건수가 통계적으로 유의미한 상관관계(0.7)가 있다.
3. 자전거 도로 수
result = stats.pearsonr(df_bic_acc_corr['사고 수'], df_bic_acc_corr['도로 수'])
print('피어슨 상관계수: {} / p-value: {}'.format(result[0], result[1]))>> 피어슨 상관계수: 0.757388672620269 / p-value: 1.1677899673918862e-05
p-value가 0.05 미만임으로 구별 자전거 교통사고 수와 자전거 도로 수가 통계적으로 유의미한 상관관계(0.75)가 있다.
자전거 도로 종류별 상관계수
데이터전처리(join)
df_bic_acc_corr.sort_values(by='사고 수', ascending=False).head()
# road_list = ['자전거전용도로 구간', '자전거보행자겸용도로 구간', '자전거전용차로 구간', '자전거우선도로 구간']
df_bic_road_csv[road_list].head()
df_road_corr = df_bic_acc_corr.join(df_bic_road_csv[road_list])
도로 종류별 상관계수와 p-value 계산
nm_list = ['자전거보행자겸용도로', '자전거우선도로', '자전거전용도로', '자전거전용차로']
corr_list = []
p_value_list = []
for item in nm_list:
result_all = stats.pearsonr(df_road_corr[item + ' 구간'], df_road_corr['사고 수'])
corr_list.append(result_all[0]) # 상관계수
p_value_list.append(result_all[1]) # p-value
print('{}: {} / {}'.format(item, result_all[0], result_all[1]))>> 자전거보행자겸용도로: 0.6474735179653053 / 0.0004673925268872105
자전거우선도로: 0.0024256092120915496 / 0.9908188567964246
자전거전용도로: 0.6090850084832358 / 0.0012314971563196727
자전거전용차로: 0.3713472876589969 / 0.06760028816487902
데이터프레임 생성
df_corr = pd.DataFrame({'도로 종류': nm_list, '상관계수': corr_list, 'p-value': p_value_list})
df_corr.sort_values(by='상관계수', ascending=False, inplace=True)
[결과 분석]
자전거보행자겸용도로, 자전거전용도로
p-value가 0.05 미만임으로 자전거보행자겸용도로, 자전거전용도로 수와 자전거 사고 수 사이 서로 연관관계 존재
자전거전용차로, 자전거우선도로
p-value가 0.05 이상으로 자전거전용차로, 자전거우선도로 수와 자전거 사고 수 사이 연관관계 없다고 할 수 있음
도로 종류별 상관계수와 p-value 비교 그래프
# 데이터 준비
x = df_corr['도로 종류']
y1 = df_corr['상관계수']
y2 = df_corr['p-value']
# 기본 설정
plt.rcParams['figure.figsize'] = (15,10)
plt.rcParams['font.size'] = 12
# 그래프
fig, ax1 = plt.subplots()
# 막대그래프 - 상관계수
ax1.bar(x, y1, color='deeppink', label='상관계수', alpha=0.7, width=0.7)
# ax1.plot(x, y1, '-s', color='green', markersize=7, linewidth=5, alpha=0.7, label='상관계수')
ax1.set_xlabel('자전거 도로 종류')
ax1.set_ylabel('상관계수')
ax1.tick_params(axis='both', direction='in')
# 꺾은선그래프 - p-value
ax2 = ax1.twinx()
ax2.plot(x, y2, '-s', color='green', markersize=7, linewidth=5, alpha=0.7, label='p-value')
# ax1.bar(x, y1, color='deeppink', label='', alpha=0.7, width=0.7)
ax2.set_ylabel('p-value')
ax2.tick_params(axis='y', direction='in')
ax1.legend(loc='upper left', fontsize=15)
ax2.legend(loc='upper right', fontsize=15)
# p-value 기준값
plt.axhline(0.05, color='gray', linestyle='--', linewidth='1', label='ddd')
plt.show()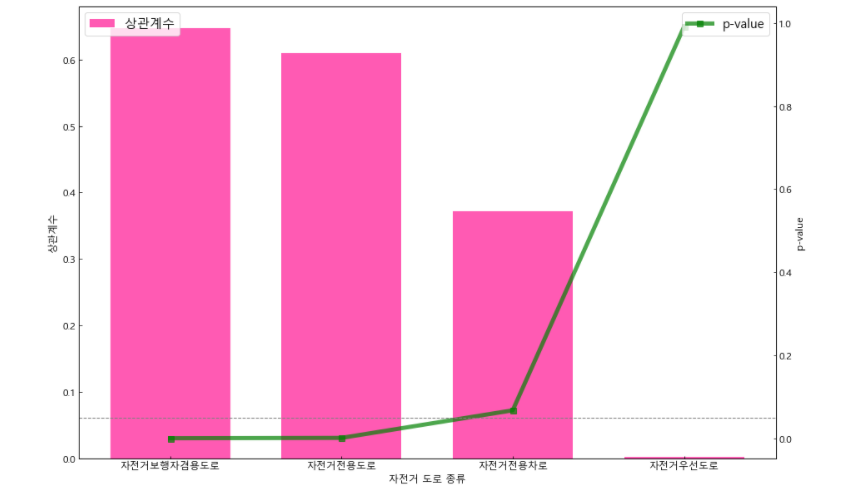
728x90
'PYTHON > K-DIGITAL' 카테고리의 다른 글
| [K-DIGITAL] 파이썬 웹 크롤링 - 뉴스 기사 스크랩 (0) | 2021.06.23 |
|---|---|
| [K-DIGITAL] 세미프로젝트1. 서울시 자전거사고 분석(4) 추가, 수정 (0) | 2021.06.22 |
| [K-DIGITAL] 파이썬을 활용한 기초 통계분석(2) 상관관계 (0) | 2021.06.22 |
| [K-DIGITAL] 파이썬을 활용한 기초 통계분석(1) 빈도 분석과 이상치 (0) | 2021.06.21 |
| [K-DIGITAL] 세미프로젝트1. 서울시 자전거사고 분석(2) 원인예측 (0) | 2021.06.19 |
댓글 영역