고정 헤더 영역
상세 컨텐츠
본문
728x90
멋쟁이사자처럼 X K-DIGITAL Training - 06.25
Selenium과 데이터베이스 이용하여 인터파크 투어 여행상품 정보 저장하기
라이브러리
import pandas as pd
import matplotlib.pyplot as plt
import time
import urllib.request
from PIL import Image
import sqlite3
from selenium import webdriver
import glob
import os
%matplotlib inlinepandas 데이터프레임 생성하여 행과 열의 데이터를 다룰 수 있게 해줌
matplotlib.pyplot 차트나 플롯(plot) 그려주는 데이터 시각화 라이브러리
time 시간 다루기 위한 모듈
urllib.request url을 가져오기 위한 파이썬 모듈
PIL.image 이미지 분석 및 처리
sqlite3 데이터베이스관리시스템, 응용프로그램에 넣어 사용하는 비교적 가벼운 데이터베이스
selenium.webdriver selenium(셀레늄) 라이브러리
glob 파일들의 리스트
os 기본 제공 모듈, 운영체제에서 제공되는 여러 기능 수행할수 있게 해줌
* urllib.request VS requests
urllib.request : 데이터를 보낼 때 인코딩하여 바이너리 형태로 보냄, 없는 페이지를 요청하면 에러 (*한글 깨짐)
requests : 데이터를 보낼 때 딕셔너리 형태로 보냄, 없는 페이지를 요청해도 에러를 띄우지 않음
SQLite 데이터베이스 준비
DB 연결
dbpath = "db_tour_info.db"
conn = sqlite3.connect(dbpath)
cur = conn.cursor()- 있다면 기존의 DB연결, 없다면 새로 생성
- connect() : 해당 데이터베이스에 연결점을 만들어줌
- cursor() : 만들어진 연결점을 오고갈 수 있게 해줌
테이블 생성
script = """
DROP TABLE IF EXISTS tour_crawl;
CREATE TABLE tour_crawl(
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT,
price INTEGER,
image TEXT
);
"""
cur.executescript(script)- cur.executescript(script) : 하나의 스크립트(문자열)로 묶인 여러 쿼리문 실행

Selenium
크롬 가상 브라우저 open
driver = webdriver.Chrome(executable_path='(driver) chromedriver.exe') 인터파크 투어 홈페이지 연결
driver.get('http://tour.interpark.com')
time.sleep(5)
원하는 여행지 입력 후 검색 버튼 클릭
driver.find_element_by_id('SearchGNBText').send_keys('독일')
driver.find_element_by_class_name('search-btn').click()
time.sleep(3)'해외여행 더보기' 버튼 클릭
driver.find_element_by_class_name('moreBtn').click()
time.sleep(3)
최대페이지 지정하여 여행상품 정보 스크랩, 데이터베이스에 저장
## maxpage 전체 결과 수로 자동 계산
# maxpage = int(driver.find_element_by_id("totalAllCnt").text) // 10 + 1
maxpage = 3
for target_page in range(1, maxpage + 1):
# 특정 자바스크립트(script)를 실행(execute)
driver.execute_script("searchModule.SetCategoryList({}, '')".format(target_page))
# 페이지 응답 기다림
time.sleep(3)
print("\n{}번째 페이지의 크롤링을 시작합니다.\n".format(target_page))
boxItems = driver.find_elements_by_class_name('boxItem')
# boxItems = driver.find_elements_by_css_selector('.panelZone > .oTravelBox > .boxList > li')
for li in boxItems:
title = li.find_element_by_class_name('proTit').text
# li.find_element_by_css_selector('h5.proTit').text
price = li.find_element_by_class_name('proPrice').text.replace(',','').replace('원~','')
# li.find_element_by_css_selector('.proPrice')
# 이미지 url
image = li.find_element_by_class_name('img').get_attribute('src')
# TEXT인 제목은 ''로 감싸주는 것에 유의
base_sql = "INSERT INTO tour_crawl(title, price, image) values('{}',{},'{}')"
sql_query = base_sql.format(title, price, image)
print('SQL Query :', sql_query[:90], "...")
cur.execute(sql_query)
conn.commit()
# 종료
driver.close()
driver.quit()
print('\n크롤링이 정상적으로 종료되었습니다.')- driver.find_element_by_class_name() : 클래스명으로 html 요소 찾기
- driver.execute_script(js, param) : 자바스크립트 코드를 인자로 넣어 해당 스크립트 실행
- cur.execute(sql) : 하나의 sql 실행

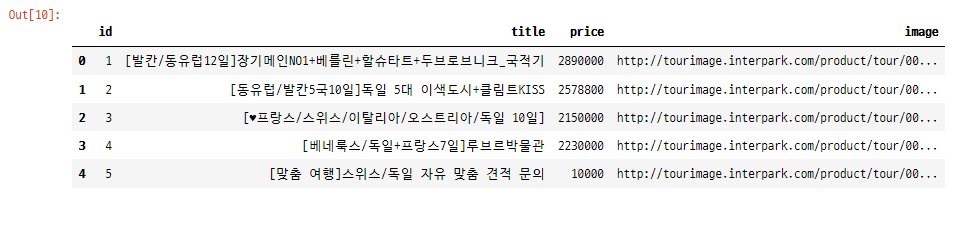
데이터프레임으로 확인
script = "SELECT * FROM tour_crawl"
df = pd.read_sql_query(script, conn)
conn.close()- pd.read_sql_query(script, conn) : 연결된 데이터베이스에 해당 쿼리를 실행하여 결과를 데이터프레임으로 받아옴
이미지 다운로드
데이터프레임에서 이미지 url 리스트
list(df.image.head())
이미지 저장할 폴더 안 정리 - 이미지가 있다면 삭제
previous_images = glob.glob('image/crawling/*.jpg') # 리스트로 반환
for image in previous_images:
os.remove(image) 리스트에 저장된 이미지 다운로드
img_urls = list(df['image'])
for index, url in enumerate(img_urls):
# 지정한 파일 명으로 저장
urllib.request.urlretrieve(url, "image/crawling/{}.jpg".format(index))
print('Downloaded image # :', index)
time.sleep(0.3)
print('Download completed!')
저장된 이미지 확인 (matplot)
fig = plt.figure(figsize=(15, 15))
rows = len(df['image']) # 전체 이미지 수에 따라 행의 수 결정
cols = 5
i = 1
for filename in glob.glob("image/crawling/*.jpg"):
# 지정한 행(rows)과 열(cols)로 구성된 격자 내에서 i번째 plot 영역을 생성
ax = fig.add_subplot(rows, cols, i)
# 불필요한 x & y축을 off
ax.axis('off')
ax.imshow(Image.open(filename))
i += 1
plt.tight_layout(pad=0) # 불필요한 여백을 0로 세팅
plt.show()- 여러 이미지를 한번에 보여주기 위해 subplot 이용

728x90
'PYTHON > K-DIGITAL' 카테고리의 다른 글
| [K-DIGITAL] 머신러닝 알고리즘(1) 회귀분석과 분류분석 (0) | 2021.06.29 |
|---|---|
| [K-DIGITAL] 인공지능과 머신러닝 (0) | 2021.06.28 |
| [K-DIGITAL] 파이썬 Selenium으로 크롤링하기(1) (0) | 2021.06.25 |
| [K-DIGITAL] 파이썬 텍스트 데이터 분석 (0) | 2021.06.25 |
| [K-DIGITAL] 파이썬 웹 크롤링 - 뉴스 기사 스크랩(2) (0) | 2021.06.23 |
댓글 영역